十一月 3, 2024
摘要:在本教程中,您将学习如何使用 PostgreSQL 窗口函数对与当前行相关的一组行执行计算。
目录
设置示例表
首先,创建两个表,名为products和product_groups,用于演示:
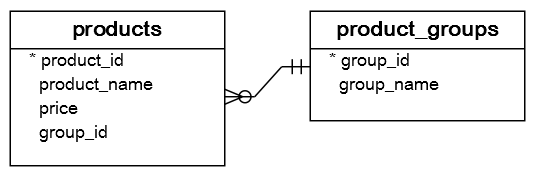
CREATE TABLE product_groups (
group_id serial PRIMARY KEY,
group_name VARCHAR (255) NOT NULL
);
CREATE TABLE products (
product_id serial PRIMARY KEY,
product_name VARCHAR (255) NOT NULL,
price DECIMAL (11, 2),
group_id INT NOT NULL,
FOREIGN KEY (group_id) REFERENCES product_groups (group_id)
);
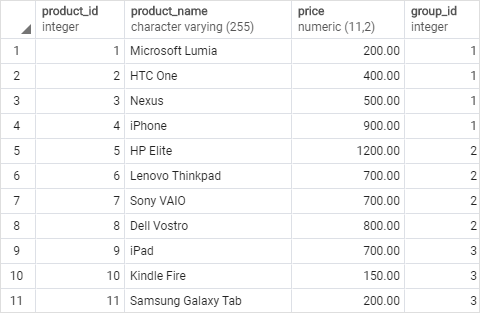
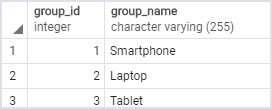
其次,向这些表中插入一些行:
INSERT INTO product_groups (group_name)
VALUES
('Smartphone'),
('Laptop'),
('Tablet');
INSERT INTO products (product_name, group_id,price)
VALUES
('Microsoft Lumia', 1, 200),
('HTC One', 1, 400),
('Nexus', 1, 500),
('iPhone', 1, 900),
('HP Elite', 2, 1200),
('Lenovo Thinkpad', 2, 700),
('Sony VAIO', 2, 700),
('Dell Vostro', 2, 800),
('iPad', 3, 700),
('Kindle Fire', 3, 150),
('Samsung Galaxy Tab', 3, 200);
PostgreSQL 窗口函数简介
理解窗口函数的最简单方法是从回顾聚合函数开始。聚合函数将一组行中的数据聚合为一行。
以下示例使用 AVG() 聚合函数计算products表中所有产品的平均价格。
SELECT
AVG (price)
FROM
products;

要将聚合函数应用于行的子集,请使用 GROUP BY 子句。以下示例返回每个产品分组的平均价格。
SELECT
group_name,
AVG (price)
FROM
products
INNER JOIN product_groups USING (group_id)
GROUP BY
group_name;
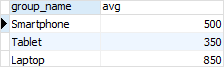
从输出中可以清楚地看到,该 AVG() 函数减少了两个示例中查询返回的行数。
与聚合函数类似,窗口函数对一组行进行操作。但是,它不会减少查询返回的行数。
术语*“窗口”*描述了窗口函数操作的行集。窗口函数从窗口中的行返回值。
例如,以下查询返回产品名称、价格、产品组名称以及每个产品组的平均价格。
SELECT
product_name,
price,
group_name,
AVG (price) OVER (
PARTITION BY group_name
)
FROM
products
INNER JOIN
product_groups USING (group_id);
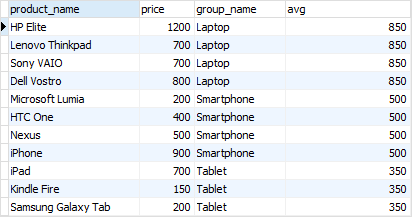
在此查询中,该AVG()函数充当窗口函数,对OVER子句指定的一组行进行操作。每组行称为一个窗口。
该查询的新语法是以下的OVER子句:
AVG(price) OVER (PARTITION BY group_name)
在此语法中,PARTITION BY将结果集的行分组,并将AVG()函数应用于每个组以返回每个组的平均价格。
请注意,在计算的顺序上,窗口函数始终在 JOIN、WHERE、GROUP BY 和HAVING 子句之后和最后的 ORDER BY 子句之前对结果集执行计算。
PostgreSQL 窗口函数语法
PostgreSQL 有一个复杂的窗口函数调用语法。下图展示了简化版本:
window_function(arg1, arg2,..)
[ FILTER ( WHERE filter_clause ) ]
OVER (
[PARTITION BY partition_expression]
[ORDER BY sort_expression [ASC | DESC] [NULLS {FIRST | LAST }]
[ frame_clause ])
在这个语法中:
window_function(arg1,arg2,…)
window_function是窗口函数的名称。有些窗口函数不接受任何参数。
FILTER 子句
FILTER子句指定,只有在 FILTER 子句中的条件计算为真的输入行才会应用到窗口函数,其他行会被丢弃。可以用 FILTER 子句选定目标行集,以应用窗口函数。
PARTITION BY 子句
PARTITION BY子句将行划分为多个组或分区,以应用窗口函数。像上面的例子一样,我们使用产品组将产品划分为组(或分区)。
PARTITION BY子句是可选的。如果省略PARTITION BY子句,窗口函数会将整个结果集视为单个分区。
ORDER BY 子句
ORDER BY子句指定应用窗口函数的每个分区中的行顺序。
ORDER BY子句使用NULLS FIRST或NULLS LAST选项可指定将空值放于结果集中的第一个还是最后一个。默认为NULLS LAST选项。
frame_clause
frame_clause定义当前分区中应用窗口函数的行子集。该行子集称为帧。可以用 ROWS BETWEEN 子句和RANGE 子句定义窗口框架,以应用窗口函数。
如果您在查询中使用多个窗口函数:
SELECT
wf1() OVER(PARTITION BY c1 ORDER BY c2),
wf2() OVER(PARTITION BY c1 ORDER BY c2)
FROM table_name;
您可以使用WINDOW子句来简化查询,如以下查询所示:
SELECT
wf1() OVER w,
wf2() OVER w,
FROM table_name
WINDOW w AS (PARTITION BY c1 ORDER BY c2);
即使您在查询中调用一个窗口函数,也可以使用WINDOW子句:
SELECT wf1() OVER w
FROM table_name
WINDOW w AS (PARTITION BY c1 ORDER BY c2);
PostgreSQL 窗口函数列表
下表列出了 PostgreSQL 提供的所有窗口函数。请注意,一些聚合函数,例如AVG()、MIN()、MAX()、SUM()和COUNT()也可以用作窗口函数。
| 名称 | 描述 |
|---|---|
| CUME_DIST | 返回当前行的相对排名。 |
| DENSE_RANK | 对当前行在其分区内无间隙地进行排名。 |
| FIRST_VALUE | 返回根据其分区内的第一行计算的值。 |
| LAG | 返回在分区内当前行之前指定物理偏移行的行处计算的值。 |
| LAST_VALUE | 返回根据其分区内最后一行计算的值。 |
| LEAD | 返回在分区内当前行之后偏移offset 行处计算的值。 |
| NTILE | 尽可能均匀地划分分区中的行,并为每行分配一个从 1 开始到参数值的整数。 |
| NTH_VALUE | 返回针对有序分区中的第 n 行计算的值。 |
| PERCENT_RANK | 返回当前行的相对排名 (rank-1) / (总行数 – 1) |
| RANK | 对当前行在其分区内的间隙进行排名。 |
| ROW_NUMBER | 从 1 开始对分区内的当前行进行编号。 |
ROW_NUMBER()、RANK() 和 DENSE_RANK() 函数
ROW_NUMBER()、RANK() 和 DENSE_RANK() 函数根据每行在结果集中的顺序为其分配一个整数。
ROW_NUMBER()函数为每个分区中的每一行分配一个序号。请参阅以下查询:
SELECT
product_name,
group_name,
price,
ROW_NUMBER () OVER (
PARTITION BY group_name
ORDER BY
price
)
FROM
products
INNER JOIN product_groups USING (group_id);
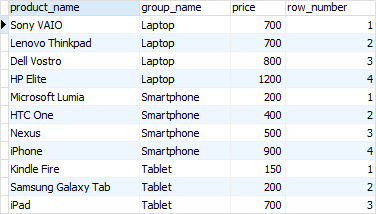
RANK() 函数在有序分区内分配排名。如果行具有相同的值,RANK()函数将分配相同的排名,并跳过下一个排名。
请参阅以下查询:
SELECT
product_name,
group_name,
price,
RANK () OVER (
PARTITION BY group_name
ORDER BY
price
)
FROM
products
INNER JOIN product_groups USING (group_id);
![]()
在笔记本电脑产品组中,Dell Vostro和Sony VAIO产品具有相同的价格,因此,它们获得相同的排名 1。组中的下一行是获得排名 3 的HP Elite产品,因为排名 2 被跳过。
与RANK()函数类似,DENSE_RANK() 函数为有序分区中的每一行分配一个排名,但排名之间没有间隙。换句话说,相同的排名被分配给多行,并且没有跳过任何排名。
SELECT
product_name,
group_name,
price,
DENSE_RANK () OVER (
PARTITION BY group_name
ORDER BY
price
)
FROM
products
INNER JOIN product_groups USING (group_id);
![]()
在笔记本电脑产品组中,排名 1 被两次分配给Dell Vostro和Sony VAIO。下一个排名是 2,分配给了HP Elite。
FIRST_VALUE 和 LAST_VALUE 函数
FIRST_VALUE() 函数返回根据其分区中的第一行计算的值,而 LAST_VALUE() 函数返回根据其分区中的最后一行计算的值。
以下语句使用FIRST_VALUE()返回每个产品组的最低价格。
SELECT
product_name,
group_name,
price,
FIRST_VALUE (price) OVER (
PARTITION BY group_name
ORDER BY
price
) AS lowest_price_per_group
FROM
products
INNER JOIN product_groups USING (group_id);
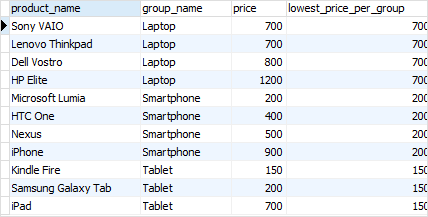
以下语句使用LAST_VALUE()函数返回每个产品组的最高价格。
SELECT
product_name,
group_name,
price,
LAST_VALUE (price) OVER (
PARTITION BY group_name
ORDER BY
price RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
) AS highest_price_per_group
FROM
products
INNER JOIN product_groups USING (group_id);
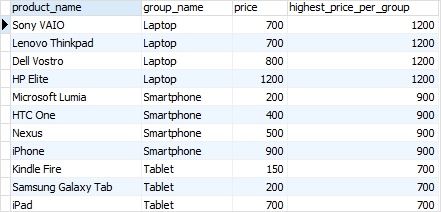
请注意,我们添加了框架子句RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING,因为默认情况下框架子句是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。
LAG 和 LEAD 函数
LAG() 函数能够访问上一行的数据,同时 LEAD() 函数可以访问下一行的数据。
LAG() 和 LEAD() 函数具有相同的语法,如下所示:
LAG (expression [,offset] [,default]) over_clause;
LEAD (expression [,offset] [,default]) over_clause;
在这个语法中:
expression– 用于计算返回值的列或表达式。offset– 当前行之前 (LAG) / 之后 (LEAD)的行数。默认为 1。default–offset超出窗口范围时的默认返回值。如果省略的话,默认为NULL。
以下语句使用LAG()函数返回上一行的价格,并计算当前行与上一行的价格之间的差值。
SELECT
product_name,
group_name,
price,
LAG (price, 1) OVER (
PARTITION BY group_name
ORDER BY
price
) AS prev_price,
price - LAG (price, 1) OVER (
PARTITION BY group_name
ORDER BY
price
) AS cur_prev_diff
FROM
products
INNER JOIN product_groups USING (group_id);
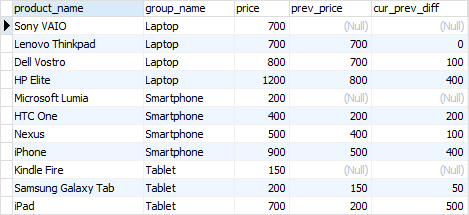
以下语句使用LEAD()函数返回下一行的价格,并计算当前行和下一行的价格之间的差值。
SELECT
product_name,
group_name,
price,
LEAD (price, 1) OVER (
PARTITION BY group_name
ORDER BY
price
) AS next_price,
price - LEAD (price, 1) OVER (
PARTITION BY group_name
ORDER BY
price
) AS cur_next_diff
FROM
products
INNER JOIN product_groups USING (group_id);
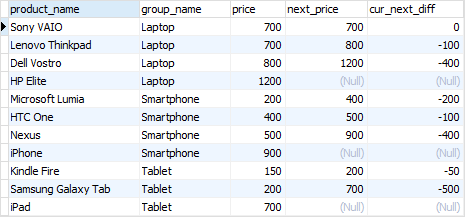
在本教程中,我们向您介绍了 PostgreSQL 窗口函数,并向您展示了一些使用它们查询数据的示例。