八月 27, 2023
摘要:在本教程中,您将学习如何使用 PostgreSQL 的cume_dist()函数,来计算一组值中某个值的累积分布。
目录
PostgreSQL cume_dist 函数概述
有时,您可能希望创建一个报告,来显示数据集中最高或最低部分的占比 x% 的值,例如按收入排名前 1% 的产品。幸运的是,PostgreSQL 为我们提供了cume_dist()函数来计算它。
cume_dist()函数返回一组值中某个值的累积分布。换句话说,它返回一个值在一组值中的相对位置。
cume_dist()函数的语法如下:
cume_dist() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
让我们详细研究一下这个语法。
PARTITION BY 子句
PARTITION BY子句将行划分为应用该函数的多个分区。
PARTITION BY子句是可选的。如果跳过它,cume_dist()函数会将整个结果集视为单个分区。
ORDER BY 子句
ORDER BY子句对应用cume_dist()函数的每个分区中的行进行排序。
返回值
cume_dist()返回一个大于 0 且小等于 1 的双精度值:
0 < cume_dist() <= 1
对于相同的平局值,该函数返回相同的累积分布值。
PostgreSQL cume_dist 示例
首先,创建一个新表,名为sales_stats,存储员工的销售收入:
CREATE TABLE sales_stats(
name VARCHAR(100) NOT NULL,
year SMALLINT NOT NULL CHECK (year > 0),
amount DECIMAL(10,2) CHECK (amount >= 0),
PRIMARY KEY (name,year)
);
其次,向sales_stats表中插入一些行:
INSERT INTO
sales_stats(name, year, amount)
VALUES
('John Doe',2018,120000),
('Jane Doe',2018,110000),
('Jack Daniel',2018,150000),
('Yin Yang',2018,30000),
('Stephane Heady',2018,200000),
('John Doe',2019,150000),
('Jane Doe',2019,130000),
('Jack Daniel',2019,180000),
('Yin Yang',2019,25000),
('Stephane Heady',2019,270000);
以下示例可帮助您更好地理解cume_dist()函数。
1) 在结果集上使用 cume_dist 函数的示例
以下示例返回 2018 年每位销售员工的销售额百分比:
SELECT
name,
year,
amount,
cume_dist() OVER (
ORDER BY amount
)
FROM
sales_stats
WHERE
year = 2018;
这是输出:
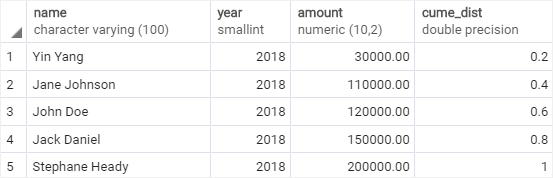
从输出中可以清楚地看出,我们可以发现 80% 的销售员工 2018 年销售额小于或等于 150K。
2) 在分区上使用 cume_dist 函数的示例
以下示例使用cume_dist()函数计算 2018 年和 2019 年每位销售员工的销售百分位。
SELECT
name,
year,
amount,
cume_dist() OVER (
PARTITION BY year
ORDER BY amount
)
FROM
sales_stats;
这是输出:
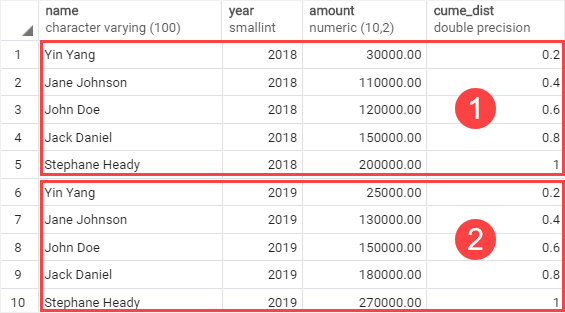
在这个例子中:
PARTITION BY子句按 2018 年和 2019 年将行分为两个分区。ORDER BY子句对应用cume_dist()函数的每个分区中每个员工的销售额从高到低进行排序。
在本教程中,您学习了如何使用 PostgreSQL 的cume_dist()函数,来计算一组值中某个值的累积分布。
了解更多
PostgreSQL 教程:窗口函数
PostgreSQL 文档:窗口函数