三月 13, 2024
摘要:在本教程中,您将了解到顺序扫描的成本估算。
目录
PostgreSQL 顺序扫描
存储引擎确定表数据在磁盘上的物理分布方式,并提供访问它的方法。顺序扫描是一种完全扫描主分支表文件的方法。在每个页面上,系统会检查每个行版本的可见性,并丢弃与查询不匹配的版本。
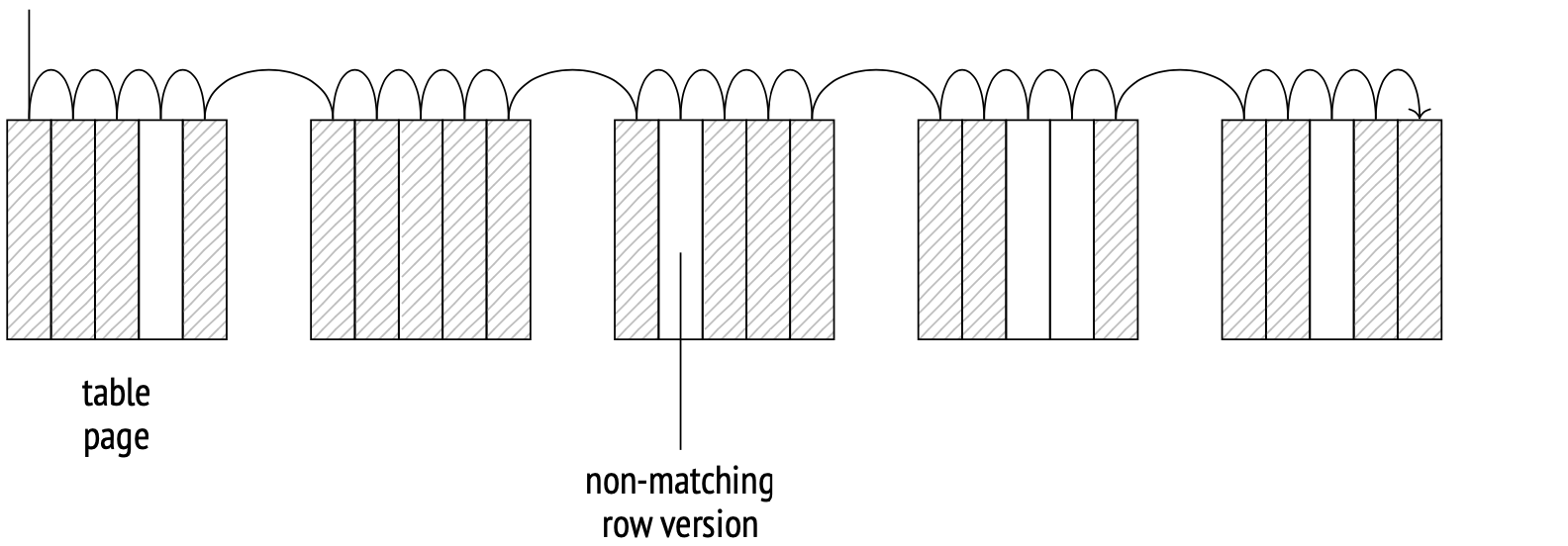
扫描是通过缓冲区来完成的。系统使用一个小型缓冲环,来防止扫描大表时从缓存中移出可能有用的数据。当另一个进程需要扫描同一个表时,它会加入到缓冲环,从而节省磁盘读取时间。因此,扫描不一定会从文件的开头开始。
顺序扫描是扫描整个表或表中很大一部分时,最具成本效益的方法。换言之,当选择率较低时,顺序扫描是有效的。在较高的选择率下,当表中只有一小部分行满足过滤条件时,通常最好使用索引扫描。
示例计划
让我们开始设置一个小的测试用例:
CREATE TABLE test7 (id integer, status integer, str text);
INSERT INTO test7 (id, status, str)
SELECT i, CAST(random() * 15 AS int), 'xxx'
FROM generate_series(1, 200000) AS s(i);
ANALYZE test7;
执行计划中的顺序扫描阶段用Seq Scan节点表示。
EXPLAIN SELECT * FROM test7;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on test7 (cost=0.00..2695.00 rows=200000 width=12)
(1 row)
行数估计值是一个基本的统计数值:
SELECT reltuples FROM pg_class WHERE relname = 'test7';
reltuples
-----------
200000
(1 row)
在估算成本时,优化器会考虑磁盘输入/输出和 CPU 处理的成本。
I/O 成本的估算值为单页获取成本乘以表中的页数(前提是页面是按顺序获取的)。当缓冲区管理器从操作系统请求页面时,系统实际上会从磁盘读取更大的数据块,因此接下来的几个页面可能已经在操作系统的缓存中了。这使得顺序获取成本(规划器权重为 seq_page_cost,默认值为 1)大大低于随机访问的获取成本(权重为 random_page_cost,默认值为 4)。
默认权重适用于 HDD 驱动器。如果您使用的是 SSD,则可以将 random_page_cost 设置得更低(seq_page_cost 通常保持为 1,以作为参考值)。成本是和硬件相关的,因此它们通常会设置在表空间级别(ALTER TABLESPACE ... SET)。
SELECT relpages, current_setting('seq_page_cost') AS seq_page_cost,
relpages * current_setting('seq_page_cost')::real AS total
FROM pg_class WHERE relname='test7';
relpages | seq_page_cost | total
----------+---------------+-------
695 | 1 | 695
(1 row)
这个公式完美地说明了由于清理晚而导致表膨胀的结果。主分支表文件越大,要获取的页面就越多,无论这些页面中的数据是否是最新的。
CPU 处理成本估计为每个行版本的处理成本之和(规划器权重为 cpu_tuple_cost,默认值为 0.01):
SELECT reltuples,
current_setting('cpu_tuple_cost') AS cpu_tuple_cost,
reltuples * current_setting('cpu_tuple_cost')::real AS total
FROM pg_class WHERE relname='test7';
reltuples | cpu_tuple_cost | total
-----------+----------------+-------
200000 | 0.01 | 2000
(1 row)
两者的总和即为计划总成本。该计划的启动成本为零,因为顺序扫描不需要任何准备步骤。
任何表过滤器都将会列在 Seq Scan 节点下方的计划中。行数估算会考虑过滤条件的选择率,成本估算将包括其处理成本。EXPLAIN ANALYZE命令会同时显示实际扫描的行数,和过滤器删除的行数:
EXPLAIN (analyze, timing off, summary off)
SELECT * FROM test7 WHERE status = 7;
QUERY PLAN
-----------------------------------------------------------------------------------------
Seq Scan on test7 (cost=0.00..3195.00 rows=13060 width=12) (actual rows=13474 loops=1)
Filter: (status = 7)
Rows Removed by Filter: 186526
(3 rows)
聚合的示例计划
请考虑以下涉及聚合的执行计划:
EXPLAIN SELECT count(*) FROM test7;
QUERY PLAN
-------------------------------------------------------------------
Aggregate (cost=3195.00..3195.01 rows=1 width=8)
-> Seq Scan on test7 (cost=0.00..2695.00 rows=200000 width=0)
(2 rows)
此计划中有两个节点:Aggregate 和 Seq Scan。Seq Scan 扫描表,并将数据传递给 Aggregate,而 Aggregate 则持续对行进行计数。
请注意,Aggregate 节点有一个启动成本:聚合本身的成本,它需要计算子节点中的所有行。估计值的计算方法是输入行数乘以任意操作的成本(cpu_operator_cost,默认为 0.0025):
SELECT
reltuples,
current_setting('cpu_operator_cost') AS cpu_operator_cost,
round((
reltuples * current_setting('cpu_operator_cost')::real
)::numeric, 2) AS cpu_cost
FROM pg_class WHERE relname='test7';
reltuples | cpu_operator_cost | cpu_cost
-----------+-------------------+----------
200000 | 0.0025 | 500.00
(1 row)
然后,估计值会加上 Seq Scan 节点的总成本。
然后,聚合的总成本会加上 cpu_tuple_cost,即生成的输出行的处理成本:
WITH t(cpu_cost) AS (
SELECT round((
reltuples * current_setting('cpu_operator_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname = 'test7'
)
SELECT 2695.00 + t.cpu_cost AS startup_cost,
round((
2695.00 + t.cpu_cost +
1 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost
FROM t;
startup_cost | total_cost
--------------+------------
3195.00 | 3195.01
(1 row)