三月 14, 2024
摘要:在本教程中,你将了解并行执行计划的成本估算。
目录
PostgreSQL 并行执行
在 PostgreSQL 9.6 及更高版本中,SQL 查询获得了并行执行计划的能力。它是这样工作的:领导者进程创建(通过管理进程)几个工作进程。然后,这些进程同时并行执行计划的一部分。然后,领导进程在 Gather 节点收集结果。由于并不忙于收集数据,领导者进程也可以参与并行计算。
您可以通过将 parallel_leader_participation 参数设置为 0,来禁用此行为,但仅限于版本 11 或更高版本。
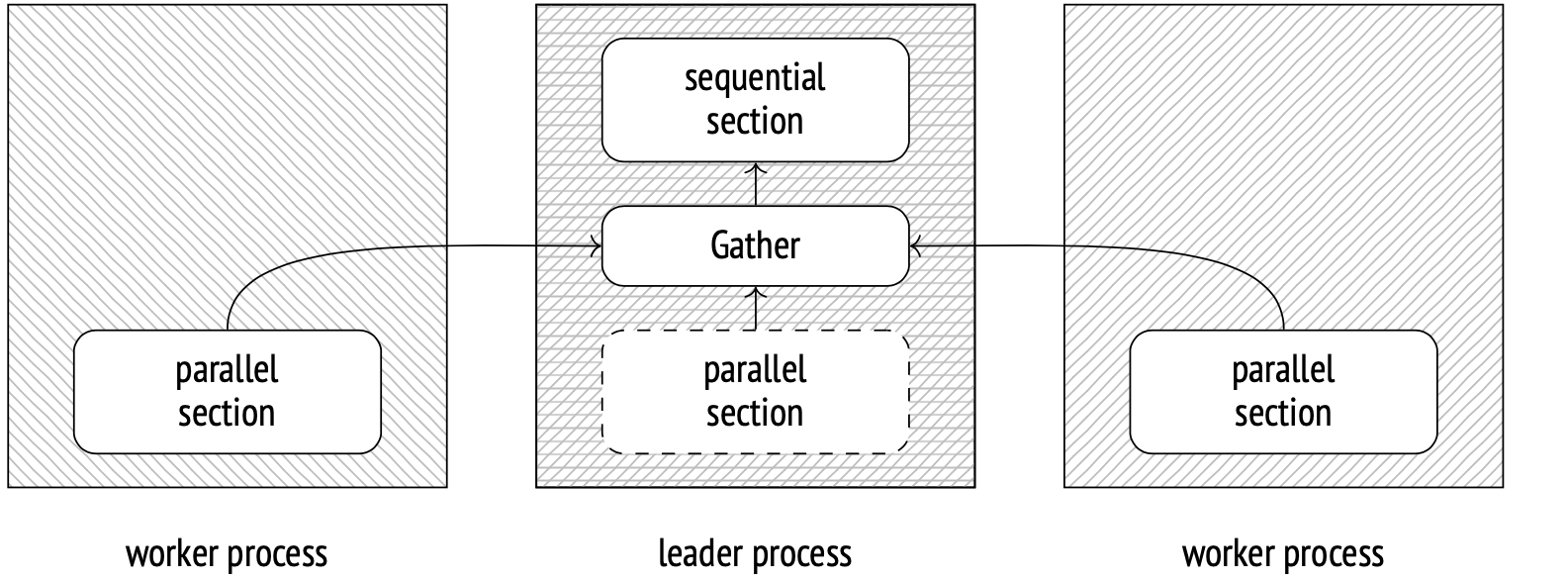
创建新进程并在它们之间发送数据,会增加总成本,因此通常最好不要使用并行执行。
此外,有些操作根本无法并行执行。即使启用了并行模式,领导进程仍会按顺序单独执行某些步骤。
并行顺序扫描
该方法的名称可能听起来有争议,声称同时是并行和顺序的,但这正是 Parallel Seq Scan 节点实际在做的事情。从磁盘的角度来看,与常规的顺序扫描相同,所有文件页面都是按顺序获取的。但是,获取是由多个并行工作的进程完成的。这些进程在一段特殊的共享内存中同步调度获取动作,以避免重复获取同一页面。
另一方面,操作系统并不会将这种获取行为当作顺序获取。从它的角度来看,只是有几个进程在请求看似随机的页面。这破坏了预读机制,而预读可以让常规的顺序扫描表现很好。这个问题已在 PostgreSQL 14 中修复,系统在开始会为每个并行工作进程分配多个连续页面,而不仅仅是一个,以便一次顺序获取。
并行扫描本身对成本效益没有多大帮助。事实上它做的只是,在常规页面获取成本的基础上,增加了进程之间的数据传输成本。但是,如果工作进程不只是扫描行,还能承担一定量的数据行处理工作(例如,聚合),则可以节省大量时间。
聚合的并行计划示例
让我们开始设置一个小的测试用例:
CREATE TABLE testpar (id integer, str text);
INSERT INTO testpar (id, str)
SELECT i, repeat(chr(65 + mod(i, 26)), 64) as str
FROM generate_series(1, 1000000) AS s(i);
ANALYZE testpar;
优化器发现这个简单的查询在对一个大表做聚合,认为最佳的执行策略是采用并行模式:
EXPLAIN SELECT count(*) FROM testpar;
QUERY PLAN
-------------------------------------------------------------------------------------------
Finalize Aggregate (cost=16625.55..16625.56 rows=1 width=8)
-> Gather (cost=16625.33..16625.54 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=15625.33..15625.34 rows=1 width=8)
-> Parallel Seq Scan on testpar (cost=0.00..14583.67 rows=416667 width=0)
(5 rows)
Gather 下面的所有节点都是该计划的并行部分。它将由所有工作进程(在本例中规划了 2 个)和领导进程(除非被 parallel_leader_participation 选项禁用)来执行。Gather 节点及其上的所有节点,都由领导进程顺序执行。
考虑下 Parallel Seq Scan 节点,该节点承担了扫描行的处理任务。rows 字段显示一个进程要处理的行数的估计值。规划了 2 个工作进程,领导者进程也会承担一部分处理任务,因此行数估计值等于表的总行数除以 2.4(2 表示工作进程,0.4 表示领导进程;工作进程越多,领导进程处理的数据量就越少)。
SELECT reltuples::numeric, round(reltuples / 2.4) AS per_process
FROM pg_class WHERE relname = 'testpar';
reltuples | per_process
-----------+-------------
1000000 | 416667
(1 row)
Parallel Seq Scan 节点成本的计算方式与 Seq Scan 成本大致相同。我们通过让每个进程处理更少的行来节省时间,但我们仍然需要扫描全表,因此 I/O 成本不会发生改变:
SELECT round((
relpages * current_setting('seq_page_cost')::real +
reltuples / 2.4 * current_setting('cpu_tuple_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname = 'testpar';
round
----------
14583.67
(1 row)
Partial Aggregate 节点聚合工作进程生成的所有数据(在本例中是对行进行计数)。
聚合成本的计算方式和之前相同,并会加上扫描成本。
WITH t(startup_cost) AS (
SELECT 14583.67 + round((
reltuples / 2.4 * current_setting('cpu_operator_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname='testpar'
)
SELECT startup_cost,
startup_cost + round((
1 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost
FROM t;
startup_cost | total_cost
--------------+------------
15625.34 | 15625.35
(1 row)
下一个节点 Gather,是由领导进程执行的。此节点启动工作进程并收集它们输出的数据。
启动一个工作进程的成本(或者几个,成本不会改变)由参数 parallel_setup_cost 定义(默认为 1000)。从一个进程发送单行数据到另一个进程的成本,由参数 parallel_tuple_cost 设置(默认为 0.1)。节点的大部分成本是在并行进程的初始化上面。它会被加到 Partial Aggregate 节点的启动成本中。还有两行结果的传输;此成本会添加到 Partial Aggregate 节点的总成本中。
SELECT
15625.34 + round(
current_setting('parallel_setup_cost')::numeric,
2) AS setup_cost,
15625.35 + round(
current_setting('parallel_setup_cost')::numeric +
2 * current_setting('parallel_tuple_cost')::numeric,
2) AS total_cost;
setup_cost | total_cost
------------+------------
16625.34 | 16625.55
(1 row)
Finalize Aggregate 节点将 Gather 节点收集的每部分数据连接在一起。其成本的估算方式与常规的 Aggregate 相同。启动成本包括三行的聚合成本和 Gather 节点的总成本(因为 Finalize Aggregate 需要其所有输出来进行计算)。在总成本之上附加的一点是,结果行的输出成本。
WITH t(startup_cost) AS (
SELECT 16625.55 + round((
3 * current_setting('cpu_operator_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname = 'testpar'
)
SELECT startup_cost,
startup_cost + round((
1 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost
FROM t;
startup_cost | total_cost
--------------+------------
16625.56 | 16625.57
(1 row)