二月 29, 2024
摘要:在本教程中,您将学习如何优化范围匹配的选择率估计。
目录
介绍
当非重复值的数量太大而无法将它们全部存储到数组中时,系统会开始使用直方图的表示形式。直方图使用多个桶来存储值。桶的数量由相同的 default_statistics_target 参数控制。
每个桶的宽度的选择,要使得值均匀地分布在它们之间(如下图中,由具有大致相同面积的矩形所指示的)。这种表示使得系统只需要存储直方图的边界值,而不用浪费存储每个桶的频率的空间。直方图不包括 MCV 列表中的值。
边界值存储在pg_stats的histogram_bounds字段中。任何一个桶中的值的总频率等于 1 / 桶数。
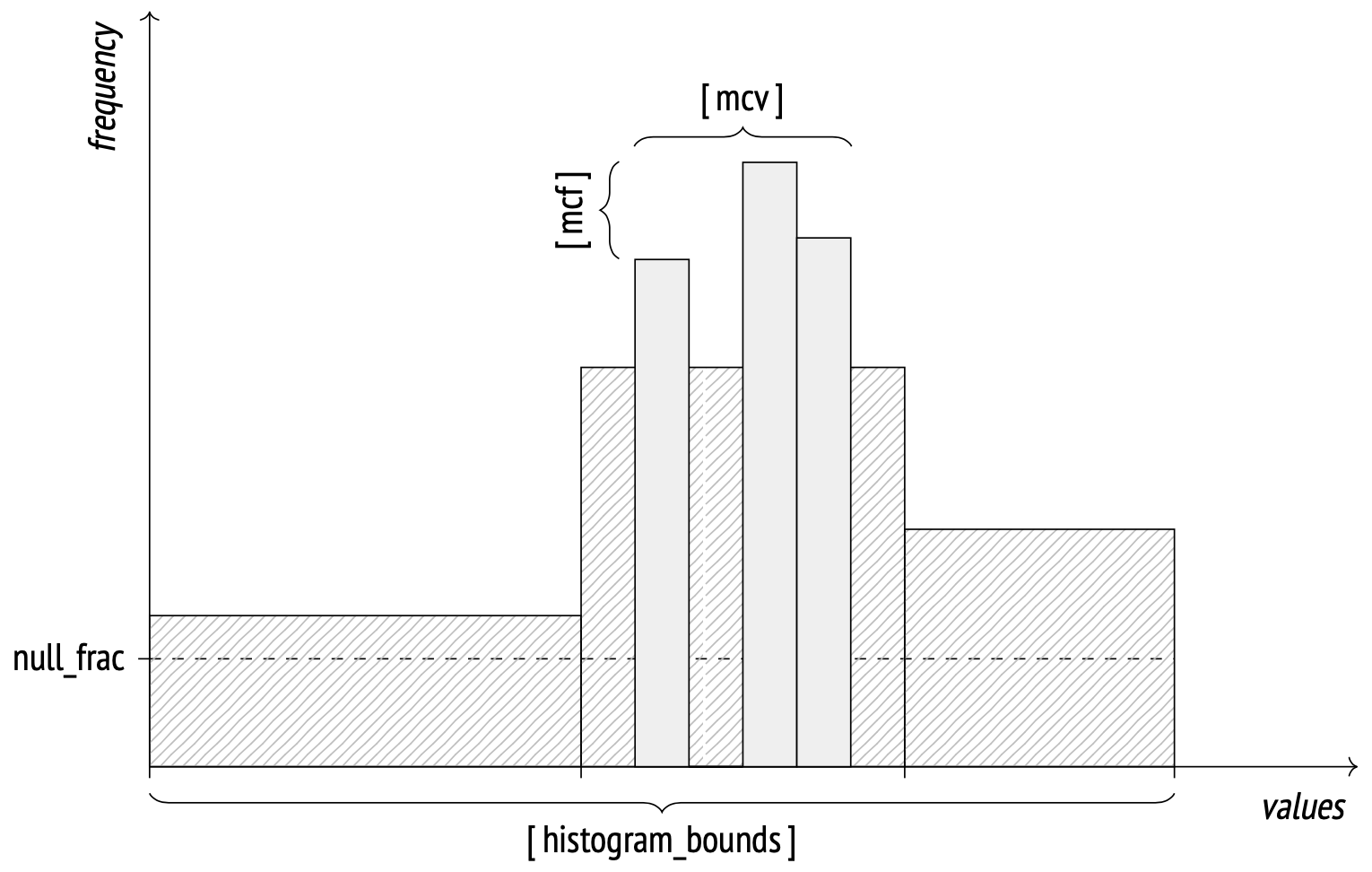
直方图是如何工作的?
让我们开始设置一个小的测试用例:
CREATE TABLE test2 (id integer, val integer);
INSERT INTO test2 (id, val)
SELECT i, CAST(random() * 400 AS integer)
FROM generate_series(1, 10000) AS s(i);
ANALYZE test2;
SHOW default_statistics_target;
default_statistics_target
---------------------------
100
(1 row)
一个直方图是以桶的边界值数组的形式存储的:
SELECT '...' || right(histogram_bounds::text, 60) AS histogram_bounds
FROM pg_stats s
WHERE s.tablename = 'test2' AND s.attname = 'val';
histogram_bounds
-----------------------------------------------------------------
...346,350,353,357,360,364,370,374,378,382,386,389,393,397,400}
(1 row)
其中,直方图和 MCV 列表,一起用于估计“大于”和“小于”操作的选择率。
例如,我们想从表中查询一些记录,根据列val进行筛选。
EXPLAIN SELECT * FROM test2 WHERE val > 302;
QUERY PLAN
----------------------------------------------------------
Seq Scan on test2 (cost=0.00..150.00 rows=2462 width=8)
Filter: (val > 302)
(2 rows)
在这里,截断值被特别地选择为两个桶之间的边界值。
此条件的选择率是 N / 桶数,其中 N 是具有匹配值的桶数(截止点右侧)。请记住,直方图中不考虑最常见的值和未定义的值。
让我们先来看看最常见值中匹配值的占比:
SELECT sum(s.most_common_freqs[
array_position(s.most_common_vals::text::integer[], v)
])
FROM pg_stats s, unnest(s.most_common_vals::text::integer[]) v
WHERE s.tablename = 'test2' AND s.attname = 'val'
AND v > 302;
sum
--------
0.0237
(1 row)
现在,让我们来看看最常见值的占比(要从直方图中排除掉):
SELECT sum(freq)
FROM pg_stats s, unnest(s.most_common_freqs) freq
WHERE s.tablename = 'test2' AND s.attname = 'val';
sum
--------
0.1442
(1 row)
val列中没有 NULL 值:
SELECT s.null_frac
FROM pg_stats s
WHERE s.tablename = 'test2' AND s.attname = 'val';
null_frac
-----------
0
(1 row)
间隔正好覆盖了 26 个桶(总共100个)。由此得出的估计行数:
SELECT round( reltuples * (
0.0237 -- from most common values
+ (1 - 0.1442 - 0) * (26 / 100.0) -- from histogram
))
FROM pg_class WHERE relname = 'test2';
round
-------
2462
(1 row)
实际行数为 2445。
当截止值不在桶的边界时,会使用线性插值来计算该桶的匹配占比。
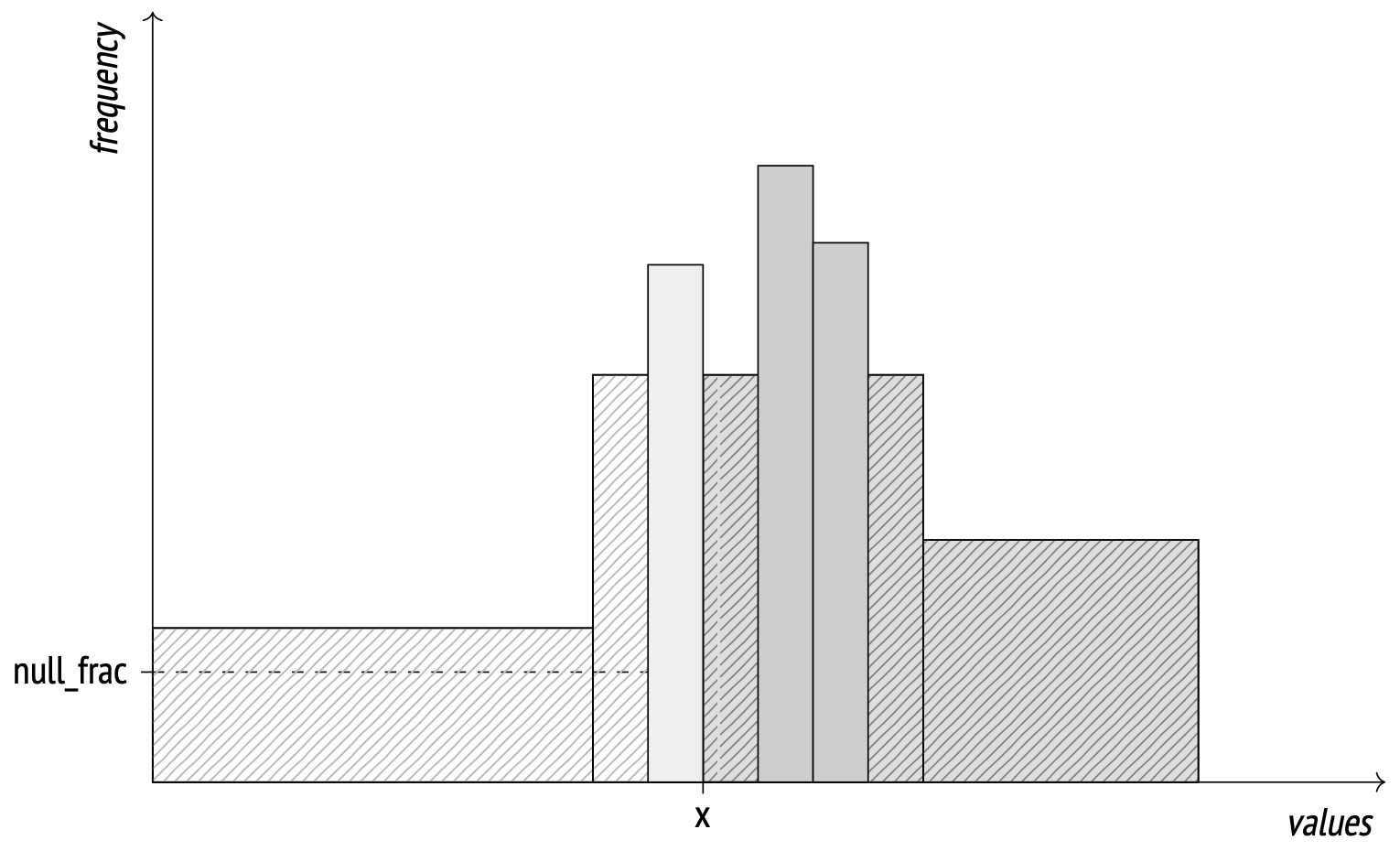
当直方图数据过时
让我们检查下列id的直方图数组:
SELECT '...' || right(histogram_bounds::text, 60) AS histogram_bounds
FROM pg_stats s
WHERE s.tablename = 'test2' AND s.attname = 'id';
histogram_bounds
-----------------------------------------------------------------
...900,9000,9100,9200,9300,9400,9500,9600,9700,9800,9900,10000}
(1 row)
然后向表中插入一批记录,并立即从表中查询新记录,根据列id进行筛选。
INSERT INTO test2 (id, val)
SELECT i, CAST(random() * 400 AS integer)
FROM generate_series(10001, 11000) AS s(i);
EXPLAIN (analyze) SELECT * FROM test2 WHERE id > 10000;
QUERY PLAN
----------------------------------------------------------------------------------------------------
Seq Scan on test2 (cost=0.00..168.00 rows=1 width=8) (actual time=1.527..1.752 rows=1000 loops=1)
Filter: (id > 10000)
Rows Removed by Filter: 10000
Planning time: 0.115 ms
Execution time: 1.809 ms
(5 rows)
实际行数为 1000,而估计行数为 1!
更新表的统计信息
不管什么时候你显著地改变了表中的数据分布后,我们都强烈推荐运行 ANALYZE。这包括向表中批量加载大量数据的情况。运行ANALYZE(或者VACUUM ANALYZE)保证规划器有表的最新统计信息。 如果没有统计数据或者统计数据过时,那么规划器在查询规划时可能会选择出很差劲的执行计划,导致在任意表上的查询性能低下。
需要注意的是,如果启用了 autovacuum 守护进程,它可能会自动运行ANALYZE;有关详细信息,请参阅参数 autovacuum_analyze_threshold 和 autovacuum_analyze_scale_factor。