二月 18, 2024
摘要:在本教程中,您将学习如何调整函数的估计返回行数。
目录
介绍
当您在 PostgreSQL 中引用/调用函数时,优化器实际上不太了解执行的成本和函数返回的行数。这并不奇怪,因为很难预测函数在做什么,以及给定的一组输入参数将返回多少行。您可能不知道的是,其实您可以告诉优化器更多有关您的函数的成本信息。
PostgreSQL 为函数提供了 ROWS 和 COST 声明。它们可用于用任何语言编写的任何 PostgreSQL 函数。这些声明允许函数设计者向规划器指示预期的行数,并提供有关函数调用的开销的提示。COST 以 CPU 周期为单位。COST 数值越高,成本越高。例如,如果在 WHERE 子句中的 AND 表达式中,有任何成本较低的函数计算返回逻辑否的结果,则不会再调用成本高的函数。ROWS 和 COST 的数值可以让规划器更好地选择使用哪种策略。
在 FROM 子句中使用函数
让我们开始设置一个小的测试用例:
CREATE TABLE people
(
first_name character varying(50),
last_name character varying(50),
mi character(1),
name_key serial PRIMARY KEY
);
INSERT INTO people(first_name, last_name, mi)
SELECT a1.p1 || a2.p2 AS fname, a3.p3 || a1.p1 || a2.p2 AS lname, a3.p3 AS mi
FROM
(SELECT chr(65 + mod(CAST(random() * 1000 AS int) + 1, 26)) AS p1
FROM generate_series(1, 30)) AS a1
CROSS JOIN
(SELECT chr(65 + mod(CAST(random() * 1000 As int) + 1, 26)) AS p2
FROM generate_series(1, 20)) AS a2
CROSS JOIN
(SELECT chr(65 + mod(CAST(random() * 1000 AS int) + 1, 26)) AS p3
FROM generate_series(1, 100)) AS a3;
CREATE INDEX idx_people_last_name ON people (last_name);
ANALYZE people;
创建了一个包含 60'000 行的简单表和一个索引。此外,让我们创建一个简单的函数,该函数将从该表中返回一组键:
CREATE FUNCTION fn_get_peoplebylname_key(lname varchar)
RETURNS SETOF int as $$
BEGIN
return query SELECT name_key FROM people WHERE last_name LIKE $1;
END $$ LANGUAGE plpgsql STABLE;
当您在 FROM 子句中调用这个函数时,优化器会做什么?
EXPLAIN (analyze) SELECT p.first_name, p.last_name, nkey
FROM fn_get_peoplebylname_key('MO%') as nkey
INNER JOIN people p ON p.name_key = nkey
WHERE p.first_name <> 'E';
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=1707.43..1730.05 rows=998 width=11) (actual time=20.986..21.034 rows=160 loops=1)
Hash Cond: (nkey.nkey = p.name_key)
-> Function Scan on fn_get_peoplebylname_key nkey (cost=0.25..10.25 rows=1000 width=4) (actual time=6.413..6.418 rows=160 loops=1)
-> Hash (cost=959.00..959.00 rows=59854 width=11) (actual time=14.350..14.350 rows=60000 loops=1)
Buckets: 65536 Batches: 1 Memory Usage: 2622kB
-> Seq Scan on people p (cost=0.00..959.00 rows=59854 width=11) (actual time=0.019..7.909 rows=60000 loops=1)
Filter: ((first_name)::text <> 'E'::text)
Planning time: 1.612 ms
Execution time: 24.283 ms
(9 rows)
pgAdmin 的图形化解释计划很好地显示出查询采用了一种哈希连接策略。
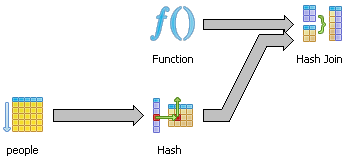
我们知道实际只返回了 160 行,但优化器假设将返回 1000 行。这是默认设置,并记录在文档中。因此,无论实际返回多少行,PostgreSQL 都将始终估计返回 1000 行。
指定估计的返回行数
PostgreSQL 为函数定义提供了一个 ROWS 参数。它是一个正数,给出了规划器期望函数会返回的估计行数。仅当函数声明为返回集合时,才允许这样做。默认假设为 1000 行。
要更改一个函数估计的返回行数,请执行以下操作:
ALTER FUNCTION fn_get_peoplebylname_key(lname varchar) ROWS 100; -- a number less than before
规划器将检测到fn_get_peoplebylname_key()会返回较少的行,并选择出一种更好的计划来执行查询。再来看一下执行计划:
EXPLAIN (analyze) SELECT p.first_name, p.last_name, nkey
FROM fn_get_peoplebylname_key('MO%') as nkey
INNER JOIN people p ON p.name_key = nkey
WHERE p.first_name <> 'E';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.54..668.25 rows=100 width=11) (actual time=5.725..5.978 rows=160 loops=1)
-> Function Scan on fn_get_peoplebylname_key nkey (cost=0.25..1.25 rows=100 width=4) (actual time=5.699..5.707 rows=160 loops=1)
-> Index Scan using name_key on people p (cost=0.29..6.67 rows=1 width=11) (actual time=0.001..0.001 rows=1 loops=160)
Index Cond: (name_key = nkey.nkey)
Filter: ((first_name)::text <> 'E'::text)
Planning time: 0.187 ms
Execution time: 6.010 ms
(7 rows)
pgAdmin 的图形化解释计划很好地显示出查询采用了一种嵌套循环策略。
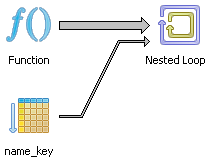
这次不是 1000 行,我们现在实际看到预估的数值只有 100 行,这是我们为函数指定的数值。通过将 ROWS 指定为较低的值,规划器将连接策略从哈希连接更改成了嵌套循环。
当然,这只是一个非常简单的示例,在现实中,您通常可能无法准确判断函数将返回多少行。但至少您可以提供更好的估计值,以替代默认行数 1000。