八月 25, 2023
摘要:在本教程中,您将学习如何使用 PostgreSQL 的RANK()函数为结果集的每一行分配排名。
目录
PostgreSQL RANK 函数介绍
RANK()函数为结果集分区内的每一行分配一个排名。
对于每个分区,第一行的排名为 1。该RANK()函数将绑定行数与绑定排名相加,以计算下一行的排名,因此排名可能不是连续的。此外,具有相同值的行将获得相同的排名。
下面说明了RANK()函数的语法:
RANK() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
在这个语法中:
- 首先,
PARTITION BY子句将结果集的行分配到应用RANK()函数的分区中。 - 然后,
ORDER BY子句指定应用该函数的每个分区中的行顺序。
RANK()函数对于创建前 N 个和后 N 个的报告非常有用。
PostgreSQL RANK() 函数演示
首先,创建一个新表,名为ranks,包含一列:
CREATE TABLE ranks (
c VARCHAR(10)
);
其次,向ranks表中插入一些行:
INSERT INTO ranks(c)
VALUES('A'),('A'),('B'),('B'),('B'),('C'),('E');
第三步,从ranks表中查询数据:
SELECT
c
FROM
ranks;
![]()
第四步,使用RANK()函数对ranks表结果集中的行进行排名:
SELECT
c,
RANK () OVER (
ORDER BY c
) rank_number
FROM
ranks;
下图显示了输出:
![]()
从输出中可以清楚地看到:
- 第一行和第二行获得相同的排名,因为它们具有相同的值
A。 - 第三、第四和第五行获得排名 3,因为
RANK()函数跳过了排名 2,并且它们都具有相同的值B。
PostgreSQL RANK() 函数示例
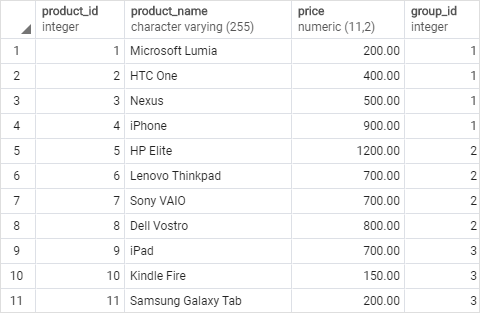
我们将使用products表来演示RANK()函数:
这张图展示了products表的数据:
1) 对整个结果集使用 PostgreSQL RANK() 函数
此示例使用RANK()函数按价格为每个产品分配排名:
SELECT
product_id,
product_name,
price,
RANK () OVER (
ORDER BY price DESC
) price_rank
FROM
products;
![]()
在此示例中,我们省略了PARTITION BY子句,因此RANK()函数将整个结果集视为单个分区。
RANK()函数计算整个结果集中每行的排名,按价格从高到低排序。
2) 使用带 PARTITION BY 子句的 PostgreSQL RANK() 函数示例
以下示例使用RANK()函数为每个产品组中的每个产品分配排名:
SELECT
product_id,
product_name,
group_name,
price,
RANK () OVER (
PARTITION BY p.group_id
ORDER BY price DESC
) price_rank
FROM
products p
INNER JOIN product_groups g
ON g.group_id = p.group_id;
![]()
在这个例子中:
- 首先,
PARTITION BY子句将产品分配到按产品组 ID (group_id) 分组的分区中。 - 其次,
ORDER BY子句按价格从高到低对每个分区中的产品进行排序。
该RANK()函数应用于每个产品组中的每个产品,并在产品组更改时重新初始化。
在本教程中,您学习了如何使用 PostgreSQL 的RANK()函数计算结果集分区中每一行的排名。
了解更多
PostgreSQL 教程:窗口函数
PostgreSQL 文档:窗口函数