由 John Doe 三月 10, 2026
最近 pgstream 针对 DDL 事件的逻辑复制,进行了一次重要的重新设计实现。

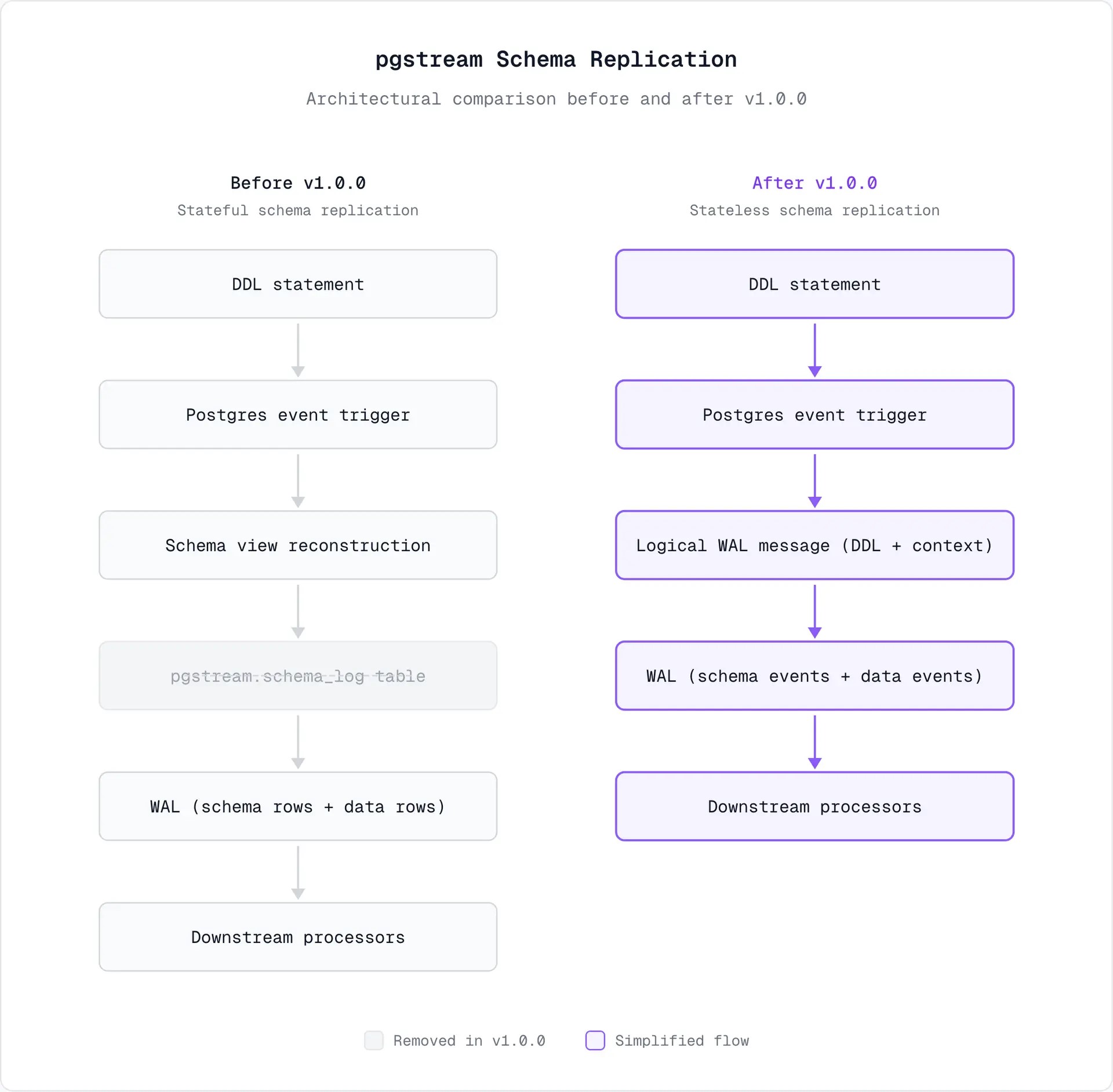
旧方案
旧版 pgstream 依靠自定义事件触发器 + Postgres 内置函数来识别 DDL 变更:
pg_event_trigger_dropped_objects处理 DROP 命令pg_event_trigger_ddl_commands处理其他所有 DDL
该触发器会:
- 查询 Postgres 系统表
- 重建一份不完整的元数据视图
- 将该视图写入
pgstream.schema_log表
这行 schema_log 记录会和普通表数据一样,以 WAL 日志的形式被复制。
这套设计的一个关键优点是:元数据变更与数据变更的顺序完全一致,因为所有变更都走 WAL。
但它也带来了明显缺点:
-
元数据视图需要手动维护,并与 Postgres 内部结构保持同步
-
只能维护部分元数据,因为是从系统表反推,而非直接来自 DDL 本身,仅支持:
- 表信息(列、索引、序列)
- 物化视图
-
每次元数据变更都多一层间接流程:DDL → 元数据视图 → 表记录 → WAL → 下游
-
元数据差异必须通过对比多条 schema_log 记录计算得出
简单说:旧方案能用,但复杂且脆弱。
pgstream.schema_log 表示例
下面是 pgstream.schema_log 表中单行数据的示例。
每一行代表某个时间点的部分元数据的快照。
元数据行
id | d61ibsq380kg0jqp3g90
version | 1
schema_name | public
created_at | 2026-02-04 10:56:51.39665
acked | True
元数据内容(JSONB 格式)
{
"tables"; [
{
"oid": "20846",
"name": "test",
"pgstream_id": "d61ibsq380kg0jqp3g9g",
"primary_key_columns": ["id"],
"columns": [
{
"name": "id",
"type": "bigint",
"nullable": false,
"unique": true,
"identity": "a",
"generated": false,
"pgstream_id": "d61ibsq380kg0jqp3g9g-1"
},
{
"name": "name",
"type": "text",
"nullable": true,
"generated": false,
"pgstream_id": "d61ibsq380kg0jqp3g9g-2"
},
{
"name": "count",
"type": "integer",
"nullable": false,
"default": "nextval('public.test_count_seq'::regclass)",
"generated": false,
"pgstream_id": "d61ibsq380kg0jqp3g9g-4"
}
],
"indexes": [
{
"name": "test_pkey",
"unique": true,
"columns": ["id"],
"definition": "CREATE UNIQUE INDEX test_pkey ON public.test USING btree (id)"
}
]
}
],
"sequences"; [
{
"oid": "21439",
"name": "test_count_seq",
"data_type": "integer",
"increment": "1",
"start_value": "1",
"minimum_value": "1",
"maximum_value": "2147483647",
"cycle_option": "NO"
}
],
"materialized_views"; []
}
新方案
在 pgstream v1.0.0 中,中间层被彻底移除。
不再把元数据状态物化到表里,新版流程是:
- 仍使用自定义事件触发器捕获 DDL(函数与旧版相同)
- 直接构建包含 DDL 语句与上下文的消息
- 通过
pg_logical_emit_message直接写入 WAL - 下游直接从事件解析变更
结果:
- 没有
schema_log表 - 没有需要重建的元数据视图
- 不需要在源库维护元数据状态
为什么这很重要
这次架构升级带来了几个关键变化:
-
所有 DDL 都会被复制,不再只是精选的部分信息
对 Postgres 目标端尤其有价值,可以完整、忠实地重放 DDL。
-
无需维护元数据视图
pgstream 不再需要镜像 Postgres 系统表结构,也不用追踪元数据形态变化。
-
中间层更少,故障点更少
元数据变更链路:
DDL 执行→WAL→下游 -
元数据复制从 “状态驱动” 变为 “事件驱动”
事实来源是 DDL 本身,而非推导出来的表示。
-
基于元数据的增量处理,无需状态对比
DDL 语句本身就是元数据增量(例如
ALTER TABLE … ADD COLUMN),无需计算差异。
简单说:pgstream 不再尝试重建元数据变更,而是直接把变更当作事件原样复制。元数据演进变成完全声明式、事件驱动。
参考
pgstream:https://github.com/xataio/pgstream