由 John Doe 七月 3, 2026
采用成熟落地方案,可将数 TB 级 Oracle 数据库迁移至 PostgreSQL,实现业务停机时间最小化,同时保障稳定可预期的数据库性能。
目录
核心迁移驱动力(为什么选择 PostgreSQL)
拥抱开源与降低成本: 避免高昂的 Oracle 许可费用,打破单一供应商锁定(Vendor Lock-in)。PostgreSQL 是由社区驱动的技术,生态开放且支持多云部署。
简化管理与运维: PostgreSQL 有成熟的线下和线上管控平台,可以自动接管数据库备份、系统更新和补丁修复,大幅减轻 DBA 的日常手动运维压力。
强大的扩展性与互操作性: PostgreSQL 原生支持丰富的扩展插件(Extensions),能够快速无缝接入当下的热门 AI 技术生态及其他创新用例。
超大型数据库(VLDB)迁移面临的核心挑战
架构与语法兼容性: Oracle 与 PostgreSQL 在数据类型、底层架构上存在显著差异。大型数据库往往积累了大量复杂的存储过程、函数和代码包,代码转换是一项艰巨的任务。
数据体量与停机时间限制: 数 TB 级别数据的物理传输高度受限于网络带宽。在严格的 SLA 标准下,实现低停机时间(Low Downtime)的数据迁移极具挑战。
性能预期与实例规格匹配: 本地物理机通常存在“过度配置”的情况,迁移至目的实例时,必须精准计算吞吐量和 IOPS,配置最合适的规格(SKU)。
高并发下的维护成本: 数据体量庞大意味着极快的数据增长率,如何在不影响生产环境的情况下定期运行维护任务(如表空间清理、监控)是一大难点。
结构化迁移生命周期(核心步骤)
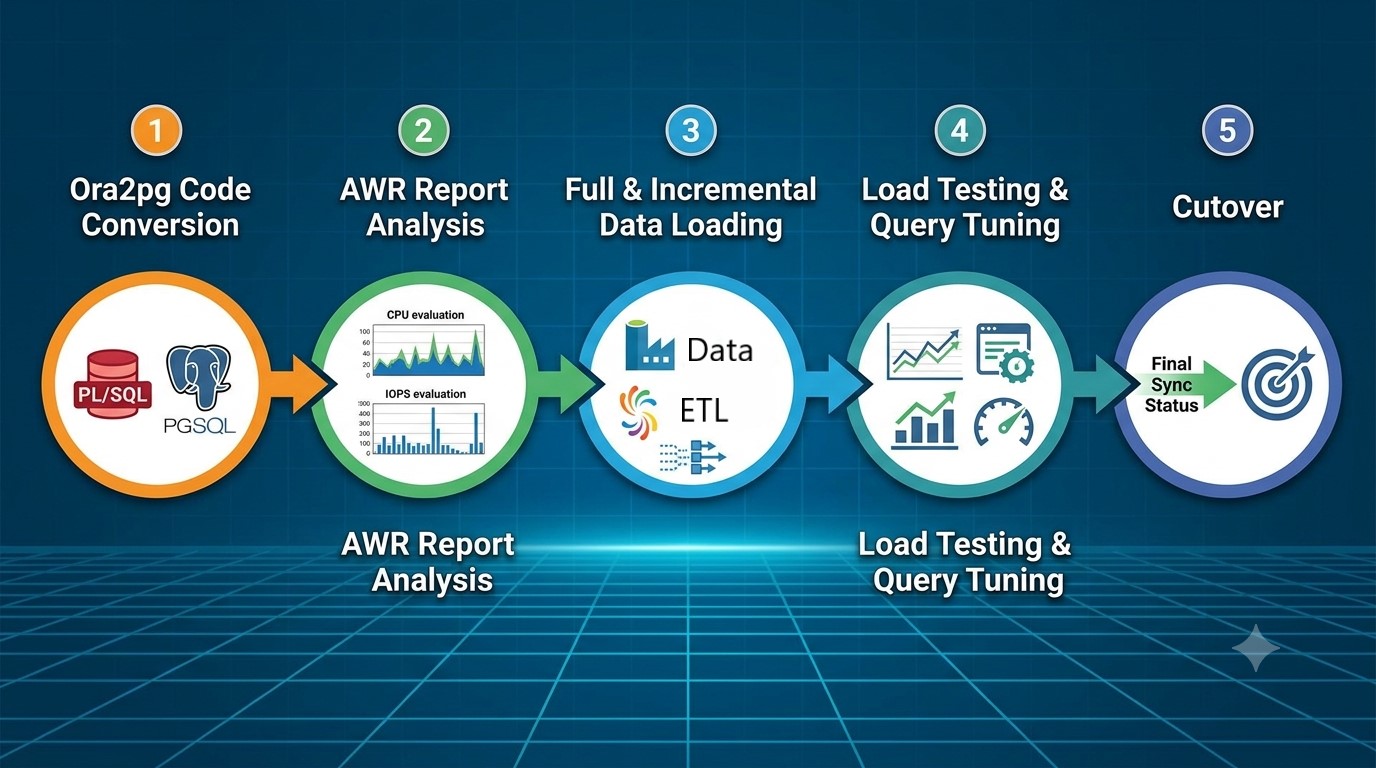
讲者总结了大型数据库迁移的标准化五步法:
架构转换与概念验证(PoC): 首要任务是转换数据架构。强烈推荐使用开源工具 ora2pg,将 Oracle 的 PL/SQL 代码转换为 PostgreSQL 的 PL/pgSQL。
目标资源规划: 提取 Oracle 在业务高峰期的 AWR(自动工作负载存储库)报告,评估 CPU 利用率和 IOPS 需求,以此为依据确定 PostgreSQL 的实例规模和存储布局。
数据加载与同步:
- 全量加载: 利用成熟的 ETL 工具进行数据迁移。
- 增量同步(降低停机时间): 结合一些准实时(Near Real-time)的复制工具,保持源库和目标库的数据同步。
验证与性能调优: 迁移后必然存在性能瓶颈。需通过压力测试定位慢查询,并进行专门的语句调优。
系统切换(Cutover): 确认性能达标后,完成双向校验并最终将业务切换至新环境。
成功案例:欧洲大型银行 16TB 核心库迁移经验
该银行将多年的 Oracle 负载成功迁移至 PostgreSQL,主要实施了以下关键策略:
分阶段数据迁移: 优先采用回溯方式迁移历史归档数据,再利用复制工具同步实时活跃数据,成功将切换停机时间压缩至“分钟级”。
并行加载策略: 针对大表,在 PostgreSQL 中重新对齐原 Oracle 的分区表结构,尝试对独立分区建立并行的数据复制管道,大幅提升加载速度。
高强度持续调优: 花费数月时间进行了 4-5 轮专门的基准测试和性能打磨,最终其查询性能甚至超越了原有的 Oracle 环境。
关键技术建议与避坑指南
重构分区策略(Partitioning): Oracle 的分区处理是自动的,而 PostgreSQL 需手动规划(或借助 pg_partman 插件)。两者的分区策略完全不同,必须在迁移前重新设计,并同步修改相关查询语句。
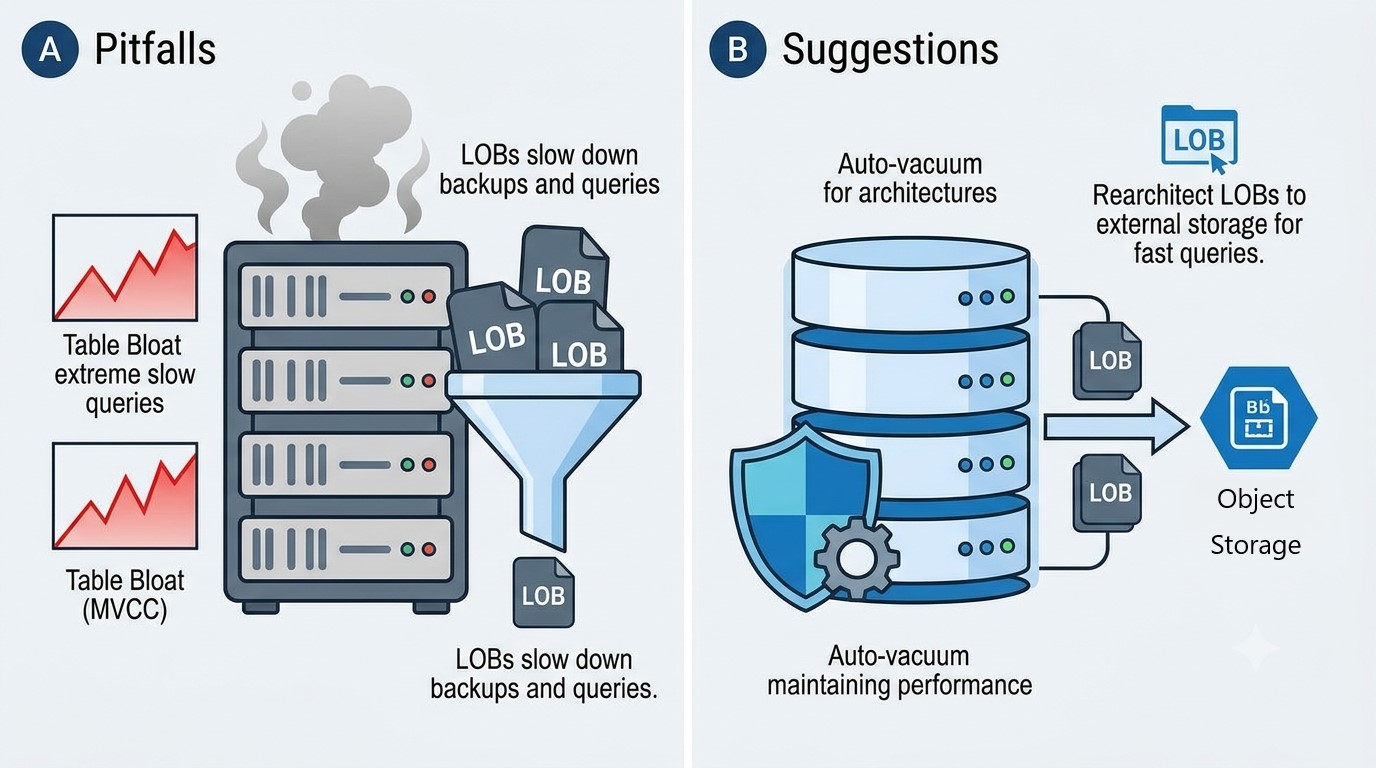
分离大对象数据(LOBs): 直接迁移 LOB(如 BLOB、CLOB)数据效率极低。强烈建议重构应用,将大对象抽离并转存至外部对象存储服务中。这不仅能减小数据库体积,还能成倍提升备份和查询速度。
警惕表膨胀(Table Bloat): PostgreSQL 采用多版本并发控制(MVCC)机制,频繁的批量更新/插入会保留旧版本数据行,导致“表膨胀”并拖垮查询性能。务必合理规划 Auto-vacuum(自动清理)进程。
关注 COPY 性能: 在进行大批量数据写入(Bulk Load)时,开发者往往忽视对原生 COPY 命令的性能调优。
切忌“小马拉大车”: 不要试图在 20TB-30TB 级别的数据量上运行 4 vCPU 的低端计算实例,必须依据 AWR 报告为其分配合理的算力底座。
参考
Migrating VLDBs from Oracle to Azure Database for PostgreSQL