四月 10, 2024
摘要:plprofiler 是 PostgreSQL 数据库系统的一个扩展,用于创建 PL/pgSQL 函数和存储过程的运行性能分析报告。
目录
在本系列教程风格的示例中,主要会演示 plprofiler 捕获性能数据时允许的不同方式。
这些示例是相互叠加的,因此最好从上到下阅读一次本文档。
假设任何对分析 PL/pgSQL 复杂代码感兴趣的人,都熟悉一般的性能测试,特别是 PostgreSQL 数据库的性能测试。另外,我们还假设读者对 pgbench 工具有基本的了解。
示例测试用例
本文档中的所有示例,都是基于一个修改后的 pgbench 数据库。修改如下:
- 在 pgbench 数据库中,构成 TPC-B 形式业务交易的 SQL 查询,已用一组 PL/pgSQL 函数实现。每个函数基本上只执行一个 TPC-B 查询。这是有意为之的,因为为了演示,我们想要一个简单且嵌套的示例。函数定义可在 pgbench_pl.sql 中找到。
- 在 pgbench_pl.profile 中有一个自定义的 pgbench 测试配置,该文件可在调用 pgbench 时与 -f 选项一起使用。
- 修改了表 pgbench_accounts。
- filler 列被展开并填充了 500 个字符的数据。
- 一个新列
category interger被添加到 aid 列的前面,并成为主键的一部分。
注意:在 PostgreSQL 9.6 中更改了 pgbench 自定义测试配置的命令语法。examples 目录中也有 9.6 版本特定的配置文件。
对 pgbench_accounts 表的修改,是基于一个客户数据库中遇到的真实案例。当然,这个 pgbench 示例案例被大大简化了。在实际情况下,对相关表的访问位于嵌套函数中,调用深度为 8,表上有几个索引可供选择,模式中包含了总共 500 个以上 PL/pgSQL 函数,和 100,000 行以上的 PL 代码。换句话说,作者曾经在大海捞针的地方寻找一根针,但被大象吃掉了。
尽管进行了简化,但这些修改产生的问题,仍然出奇一致地模拟了原始情况。TPC-B 事务仅根据 aid 列访问 pgbench_accounts 表,因此这是 WHERE 子句中唯一可用的键值部分。但是,由于表行现在的宽度为 500 字节以上,并且索引相当小,因此相比于堆表扫描,PostgreSQL 查询优化器仍会选择索引扫描。基于可选的执行路径,这是正确的选择,因为顺序扫描会更糟。
pgbench_plprofiler=# explain select abalance from pgbench_accounts where aid = 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------
Index Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.42..18484.43 rows=1 width=4)
Index Cond: (aid = 1)
由于索引的第一列不是 WHERE 子句的一部分,因而也不是索引条件的一部分,因此会导致对整个索引进行全面扫描!不幸的是,除了这个 explain 输出之外,这个细节无处可见。然后,只有当你知道该索引的定义时,才会注意到它。例如,如果我们在基准测试运行后查看 pg_stat_* 表,它们只会告诉我们,对 pgbench_accounts 的所有访问都是通过对主键的索引扫描完成的,并且所有这些扫描都返回了一行。人们通常会认为“这里没有错”。
最重要的是,由于访问该表的查询永远不会出现在任何统计信息中,因此我们永远不会看到,在 10 倍 pgbench 缩放因子的场景下,每个查询已经花费了 30 毫秒。想象一下,在我们放大缩放因子后,情况会变成什么样子。
准备 pgbench 测试数据库的完整脚本,可在 prepdb.sh 中找到。
为了获得一个性能基线,在具有 32GB 内存的 8 核机器上,整个数据库使用了 8GB 的共享缓冲区,以 24 个客户端进行 5 分钟的 pgbench 测试,测试 5 次取平均值,结果为 136 TPS(是的,就是这么糟糕)。
[postgres@localhost examples]$ pgbench -n -c24 -j24 -T300 -f pgbench_pl.profile
transaction type: Custom query
scaling factor: 1
query mode: simple
number of clients: 24
number of threads: 24
duration: 300 s
number of transactions actually processed: 40686
latency average: 176.965 ms
tps = 135.580039 (including connections establishing)
tps = 135.589426 (excluding connections establishing)
是时候创建一份性能报告了。
常规命令语法
plprofiler 工具的常规语法是
plprofiler COMMAND [OPTIONS]
所有命令的通用选项是,控制数据库连接的选项。这些是
| 选项 | 描述 |
|---|---|
-h, --host=HOST |
要连接到的主机。 |
-p, --port=PORT |
数据库服务器正在监听的端口号。 |
-U, --user=USER |
数据库用户名。 |
-d, --dbname=DB |
数据库名称、连接字符串或 URI。 |
plprofiler help [COMMAND]可向您展示,比本文档提供示例所解释的更详细信息。
在下面的示例中,假设环境变量PGHOST、PGPORT、PGUSER和PGDATABASE都已设置成连接到 pgbench_plprofiler 数据库,这是使用 prepdb.sh 脚本创建的。上面的连接参数会被省略,以使示例更可读。出于安全原因,无法在命令行上指定密码。如果您的数据库需要密码验证,请在~/.pgpass文件中进行必要的设置。
使用 plprofiler 工具执行 SQL
在测试数据库中安装 plprofiler 扩展后,要生成一份 PL/pgSQL 函数的性能报告,最简单的方法是使用 plprofiler 工具运行它们,并让它直接从后端收集的本地数据创建 HTML 报告。
plprofiler run --command "SELECT tpcb(1, 2, 3, -42)" --output tpcb-test1.html
由于不是 HTML 报告的所有信息都是在命令行上指定的,因此在 SQL 语句完成后,该工具会使用一个配置文件启动$EDITOR,因此您有机会在呈现 HTML 之前更改一些默认值。最后,这将在当前目录中创建报告tpcb-test1.html,该报告看起来会与概述中显示的报告相似。
对于这种性能分析方式,需要记住的一件事是,在数据库会话(连接)中首次调用函数时,PL/pgSQL 中存在大量开销。PL/pgSQL 函数调用处理程序必须解析整个函数定义,并为其创建保存的 PL 执行树。某些类型的 SQL 语句也将被解析和验证。由于这些原因,像这样调用一个实际上微不足道的 PL/pgSQL 示例,可能会产生非常误导的结果。
为避免这种情况,应连续多次调用该函数。文件 tpcb_queries.sql 包含了对tpcb()函数的 20 次调用,可以这样来执行
plprofiler run --file tpcb_queries.sql --output tpcb-test1.html
分析第一份性能报告
上一个plprofiler命令(使用了 --file 选项)生成的报告,应该大致如下(这类将 SVG 火焰图从默认宽度 1200 像素缩小到了 800 像素,以便在 bitbucket 上更好地嵌入到 markdown 中),还将 tabstop 设置为 4,这也是 PL 函数的 SQL 文件的格式:
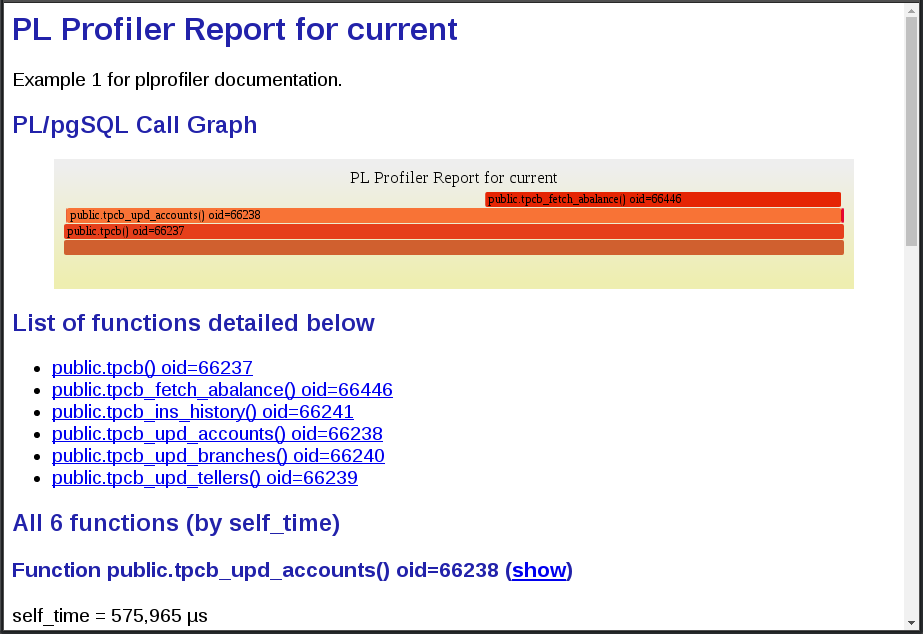
继续并在单独的窗口或选项卡中打开实际的 HTML 版本,以便能够与之交互。
在火焰图顶部突出的是两个函数tpcb_fetch_abalance()及其调用者tpcb_upd_accounts()。当您将鼠标悬停在火焰图中的tpcb_upd_accounts()条目上时,您会看到它实际上占了 PL/pgSQL 函数内部总执行时间的 99% 以上。
为了更仔细地检查这个函数,我们在报告中向下滚动到tpcb_upd_accounts()的详情部分,然后单击 (show) 链接,我们可以看到函数的源代码,以及执行每一行花费的时间。
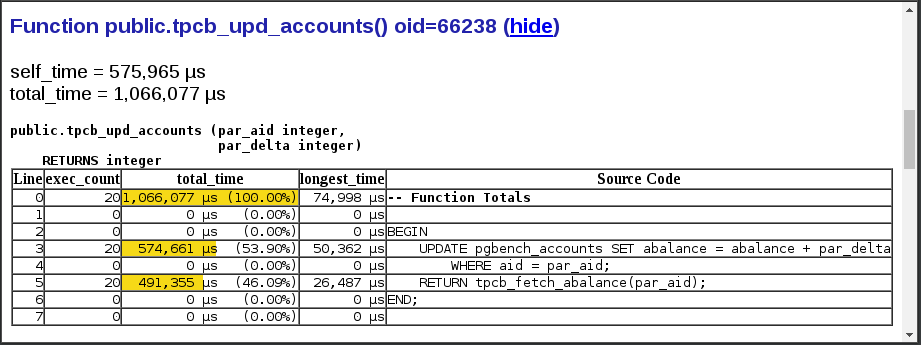
显然,在 UPDATE 语句中访问 pgbench_accounts 表时存在问题。这个函数占用了我们 99% 的时间,其中 50% 花在了一条 UPDATE 语句上。这不正常。
同样,如果我们检查函数tpcb_fetch_abalance()的细节,我们会发现相同的访问路径(通过 pgbench_accounts.aid 执行单行 SELECT)具有完全相同的性能问题。
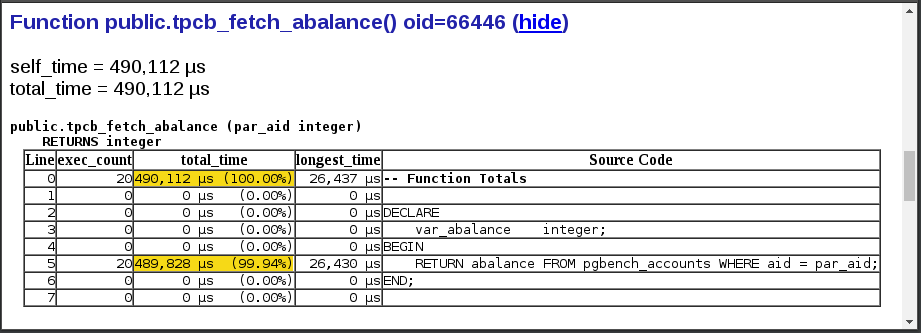
当然,这些都是以有经验的程序员狩猎大象的方式进行的练习。我故意在房间的中间放了一头大象,然后找到了它。没什么好奇怪的。它就是这样,人为复现了一个现实世界遇到的问题。你将不得不相信我的话,在真实生产环境的案例中发现问题,几乎和这个例子一样容易。
我们暂时不打算解决实际问题(缺少/错误的索引),而是探索调用 plprofiler 的替代方法。这样,我们就可以基于相同的问题场景,比较所有不同的方法。
通过探测应用捕获性能数据
有时,向应用程序中添加探测调用,可能比提取独立查询更容易,独立查询可由 plprofiler 通过 --command 或 --file 选项运行。要添加探测调用,可以在应用程序代码中的要害位置,添加一些 plprofiler 函数调用。对于 pgbench,对应的应用程序代码是自定义测试配置 pgbench_pl.collect.profile。
\set nbranches :scale
\set ntellers 10 * :scale
\set naccounts 100000 * :scale
\setrandom aid 1 :naccounts
\setrandom bid 1 :nbranches
\setrandom tid 1 :ntellers
\setrandom delta -5000 5000
SELECT pl_profiler_enable(true);
SELECT tpcb(:aid, :bid, :tid, :delta);
SELECT pl_profiler_collect_data();
SELECT pl_profiler_enable(false);
函数pl_profiler_enable(true)会触发加载 plprofiler 扩展,并开始在本地数据的哈希表中累积分析数据。函数pl_profiler_collect_data()可将本地数据复制到共享哈希表中,并将本地数据计数器重置为零。
有了这个更改后的应用程序代码,我们可以运行
plprofiler reset
pgbench -n -c24 -j24 -T300 -fpgbench_pl.collect.profile
reset命令会删除共享哈希表中的所有数据。在 pgbench 完成之后,我们使用共享数据(已经由pl_profiler_collect_data()函数复制到共享哈希表中的数据)来生成一份报告。
plprofiler report --from-shared --name "tpcb-using-collect" --output "tpcb-using-collect.html"
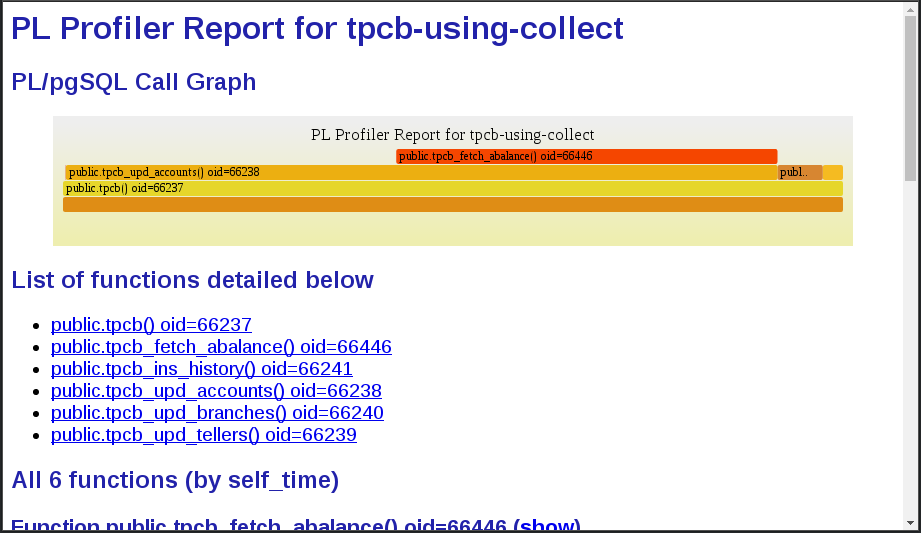
性能报告中似乎只有细微的变化。用于更新 pgbench_branches 和 pgbench_tellers 表的函数,在第一份报告中几乎不可见,现在使用了 5.81% 和 2.60% 的时间。这可能看起来不多,但随着对 pgbench_accounts 的访问被影响了,这实际上是巨大的。差异是由并发性(24 个客户端)引起的。
按定时间隔收集统计信息
我们可以将其配置为,每 N 秒将本地数据复制到共享哈希表(并重置本地数据计数器),而不是在每次单独的事务后收集本地数据。收集发生在每次事务提交/回滚时,以及当 PL/pgSQL 函数退出且定时器到点时。
为此,我们使用一个略有不同的 pgbench 自定义测试配置 pgbench_pl.interval.profile。
\set nbranches :scale
\set ntellers 10 * :scale
\set naccounts 100000 * :scale
\setrandom aid 1 :naccounts
\setrandom bid 1 :nbranches
\setrandom tid 1 :ntellers
\setrandom delta -5000 5000
SET plprofiler.enabled TO true;
SET plprofiler.collect_interval TO 10;
SELECT tpcb(:aid, :bid, :tid, :delta);
这里没有显示结果报告,因为它与前一份报告几乎相同。
通过 ALTER USER 收集统计信息
上述操作也可以在不更改应用程序代码的情况下完成。比如,我们可以将 plprofiler 添加到postgresql.conf文件中
shared_preload_libraries = 'plprofiler'
(这需要重新启动 PostgreSQL 服务器),然后按如下方式配置应用程序的用户:
ALTER USER myuser SET plprofiler.enabled TO on;
ALTER USER myuser SET plprofiler.collect_interval TO 10;
这与最后一个示例具有完全相同的效果。当然,它要求应用程序在执行ALTER USER ...语句后,重新连接以开始收集数据,并且最好在我们完成分析后,再次重新连接执行相应的ALTER USER ... RESET ...命令。因此,这仍然不适合分析真实生产系统,因为它具有太大的影响。
对生产系统进行性能分析
警告:在生产系统上进行调试和分析,是一件有风险的工作,应尽可能避免。
不幸的是,有时这是不可避免的。出于这个原因,plprofiler 提供了一些选项,旨在将其对性能的影响降到最低。
与前面的示例一样,下面演示的分析方法,需要从postgresql.conf文件中预加载 plprofiler。
shared_preload_libraries = 'plprofiler'
这本身不是问题。plprofiler 会被加载并将所有回调函数放入 PL 探测钩子中。所有这些函数执行的第一件事是,检查是否启用了分析。如果未启用任何内容,则该检查相当于在所有回调函数的开头计算一次
if (!bool_var && int_var != ptr->int_var) return;
在每次函数进入/退出,以及每个 PL 语句(仅具有实际运行时功能的语句)开始/结束时,会调用一个回调函数。在大型业务系统中,这种开销可以忽略不计。
配置好shared_preload_libraries(重新启动数据库服务器使其生效),并且共享数据为空(运行plprofiler reset),我们在后台启动pgbench。稍等一会儿,我们通过检查系统视图pg_stat_activity,获得一个 pgbench 客户端的后端 PID。有了这个 PID,我们就可以运行
plprofiler reset
plprofiler monitor --pid <PID> --interval 10 --duration 300
plprofiler report --from-shared --name tpcb-using-monitor --output tpcb-using-monitor.html
plprofiler monitor命令会使用ALTER SYSTEM ...和SELECT pg_reload_conf()启用性能分析,并在指定的持续时间后将其关闭。这显然只适用于 PostgreSQL 9.4 或更高版本的数据库。与任何数据库维护操作一样,这应该只在连接丢失安全的环境中进行,因为在监控过程中丢失连接将会永久保留这些设置。
省略 --pid 选项,将会导致所有活动的后端,保存其在指定时间间隔内的统计信息。
解决性能问题
在本教程的最后一章中,我们来修复人为引入的性能问题,就像在真实环境中所做的那样。我们创建缺失的索引。
CREATE INDEX pgbench_accounts_aid_idx ON pgbench_accounts (aid);
有了这些索引,我们再次使用最后一种方法捕获性能数据,来生成本教程的最后一份报告。
plprofiler reset
plprofiler monitor --pid <PID> --interval 10 --duration 300
plprofiler report --from-shared --name tpcb-problem-fixed --output tpcb-problem-fixed.html
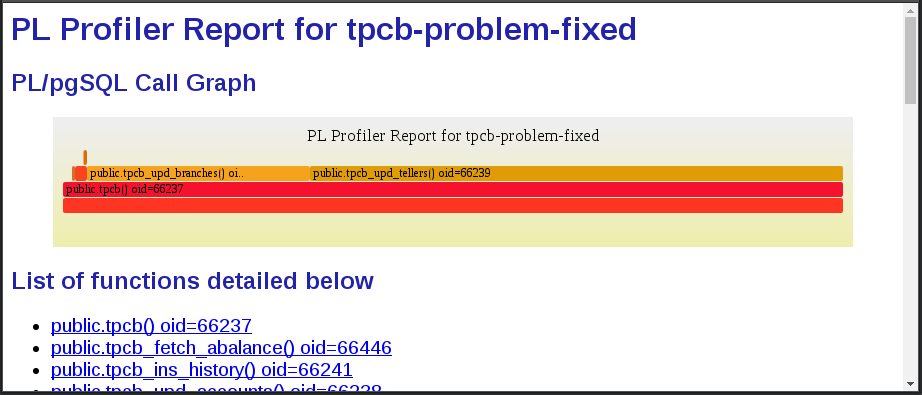
性能分析报告现在完全相反。访问 pgbench_accounts 只是总花费时间的一小部分(1.52%,其中 0.44% 用于获取新帐户余额)。对 pgbench_tellers 和 pgbench_branches 的访问占据了大幅画面。这才是在共享缓冲区内运行的 pgbench 应该表现出现的情况。由于 tellers 和 branches 表非常小,因此存在大量的行级锁争用和不断膨胀的情况。
pgbench 的整体性能从最初的 136 TPS 上升到了令人惊叹的水平。
transaction type: Custom query
scaling factor: 1
query mode: simple
number of clients: 24
number of threads: 24
duration: 300 s
number of transactions actually processed: 1086292
latency average: 6.628 ms
tps = 3620.469364 (including connections establishing)
tps = 3620.869051 (excluding connections establishing)
添加一个额外的索引,性能提升了 27 倍。
并非所有的性能问题都这样容易解决。但是希望 plprofiler 能帮助你快速找到问题,这样你就有更多时间来修复它们。