由 John Doe 二月 2, 2026
摘要:在本文中,我们将了解 PostgreSQL 事务 ID 快速分配带来的数据冻结问题,以及相关的解决方案。
目录
事务号分配场景: 用例
下面我们在 PostgreSQL 的数据库中,创建一个表,插入足够数量的数据。
CREATE UNLOGGED TABLE t_large (id) AS
SELECT i FROM generate_series(1, 250000000) AS s(i);
构造一个预备事务,让后台 autovacuum 无法通过冻结数据推进系统中最老的事务 ID。
BEGIN;
INSERT INTO t_large (id) VALUES (250000001);
PREPARE TRANSACTION 't1';
注意:如果你需要使用预备事务,你会希望把 max_prepared_transactions 至少设置为 max_connections 一样大,这样每一个会话都可以有一个预备事务待处理。
使用 pg_resetwal 手动模拟分配事务 ID,将事务 ID 直接推进到 21 亿。
pg_ctl stop
pg_resetwal --pgdata=$PGDATA --next-transaction-id=2100000000
dd if=/dev/zero of=$PGDATA/pg_xact/07D2 bs=8192 count=24
pg_ctl start
使用存储过程的异常处理块,更新全表数据,快速消耗系统中的事务 ID。
SET log_min_messages = 'ERROR';
SET client_min_messages = 'ERROR';
DO $$ DECLARE
blkid integer := 0;
posid integer := 1;
BEGIN
LOOP
BEGIN
PERFORM 1 FROM t_large WHERE ctid = (blkid, posid)::text::tid FOR UPDATE;
EXCEPTION WHEN OTHERS THEN
RAISE WARNING 'Exception for row: (%, %)', blkid, posid;
END;
IF FOUND THEN
posid := posid + 1;
ELSIF posid = 1 THEN
EXIT;
ELSE
blkid := blkid + 1;
posid := 1;
END IF;
END LOOP;
END$$;
上面的命令运行一段时间后,数据库出现错误:“数据库不接受命令”,PostgreSQL 陷入停机状态。
ERROR: database is not accepting commands that assign new transaction IDs to avoid wraparound data loss in database "postgres"
HINT: Execute a database-wide VACUUM in that database.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.
事务号分配场景: 内部原理
下面是我们在 PostgreSQL 中运行上面的存储过程时,数据库系统全局事务 ID 发生的变化:
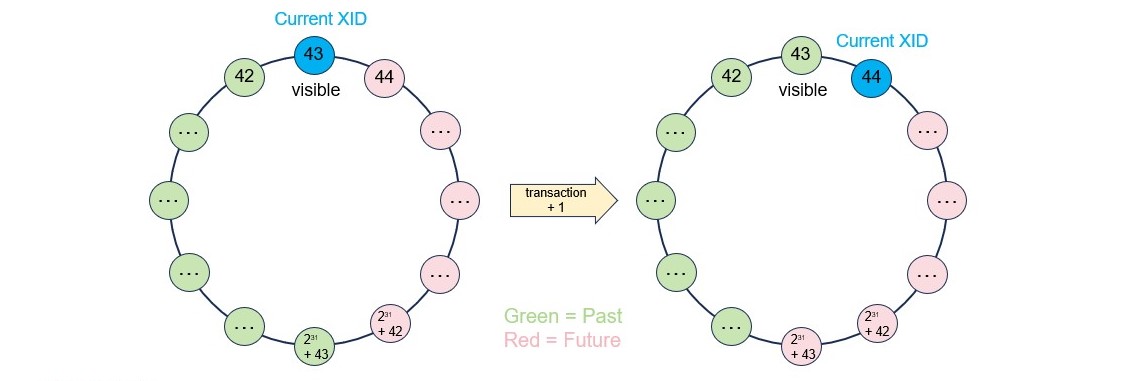
- PostgreSQL 使用了子事务,来实现存储函数中的异常处理代码块。
- 每个事务/子事务都有一个事务 ID,它有点像数据库系统的运行时间。
- 每行都有两个默认的隐藏属性 xmin 和 xmax,这两个属性分别保存了创建和更改它们的事务/子事务的 ID。
- 系统中最多出现的事务 ID 数目约为 20 亿,在超过该数目后,MVCC 的机制将无法正常工作。
事务号分配场景: 思考
问题影响
- 需要定期扫描所有数据行,进行事务 ID 的冻结操作,周期时长由 autovacuum_freeze_max_age 参数控制,默认为 2 亿次事务。
- 如果再叠加长事务/慢查询的发生,会出现事务 ID 耗尽,数据库停止服务。
- 系统需要存储管理所有未冻结事务的状态,容易出现 pg_xact、pg_subtrans 和 pg_multixact 缓存访问的等待事件,整体性能会下降。
冻结频率与事务吞吐量
在 PostgreSQL 中,元组冻结操作(通过VACUUM命令执行)的频率与每秒修改数据的事务数(TPS,包括 INSERT、UPDATE、DELETE 操作)成正比。由于 PostgreSQL 采用 32 位事务 ID(XID),其事务 ID 会在累计约 20 亿次事务后发生回卷,因此高吞吐系统(高写入 TPS)需要更频繁地执行冻结操作,以防止因事务 ID 回卷造成数据丢失。
数据表达到默认的 autovacuum_freeze_max_age 阈值的耗时,会随写入 TPS 的提升而缩短。
| 事务吞吐量 TPS | 达到 20 亿事务阈值的时长 | 执行冻结操作的周期 |
|---|---|---|
| 1000 | 23 天 | 2.3 天 |
| 10000 | 2.3 天 | 5.5 小时 |
| 100000 | 5.5 小时 | 33 分钟 |
| 1000000 | 33 分钟 | 3.3 分钟 |
注意:以上数据基于持续、高吞吐量的写入业务场景测算,部分为理论值,旨在直观体现超高事务吞吐量对系统的影响。
应对方案
- 配置监控告警,检查事务 ID 耗尽
- 配置监控告警,检查子事务的使用情况
- 配置监控告警,检查长时间运行的事务
Redrock Postgres 的解决方案
Redrock Postgres 是基于回滚日志记录位置实现的子事务,这些子事务不过是事务执行过程中的一个临时标记。子事务使用和所属事务块同样的事务 ID,它们并不需要分配独立的事务 ID,不会对系统造成任何风险。
另外,在 Redrock Postgres 中,内部的事务 ID 是 8 字节的长度,可以近乎无限使用,无需担心事务 ID 用尽的风险。每个事务会记录回滚日志,用于回滚数据的修改和事务,事务状态的维护和管理更简单且更稳定。