由 John Doe 四月 6, 2026
摘要:在本文中,我们将了解 PostgreSQL 事务 ID 快速分配带来的数据冻结问题,以及相关的解决方案。
目录
事务号分配场景: 用例
我们知道,在 PostgreSQL 的存储过程中使用异常逻辑,需要用到子事务。我们先创建一个简单的函数,该函数可以根据指定的 depth 参数,增加异常逻辑的嵌套深度:
CREATE OR REPLACE FUNCTION generate_subtrans_load(p_id int, depth int)
RETURNS void AS $$
BEGIN
IF depth > 0 THEN
BEGIN
PERFORM generate_subtrans_load(p_id, depth - 1);
EXCEPTION WHEN OTHERS THEN NULL;
END;
ELSE
INSERT INTO penalty_test VALUES (p_id, 'Deep Stack');
END IF;
END;
$$ LANGUAGE plpgsql;
下面我们来通过一个简单的存储过程,循环调用上面带异常逻辑的函数进行测试:
CREATE OR REPLACE PROCEDURE subtrans_test(depth integer)
AS $$
DECLARE
i int;
v_target_rows int := 5000;
BEGIN
DROP TABLE IF EXISTS penalty_test;
-- 显式保留行,以便 COMMIT 不会清空表
CREATE TEMP TABLE penalty_test (id int, val text) ON COMMIT PRESERVE ROWS;
COMMIT;
FOR i IN 1..v_target_rows LOOP
PERFORM generate_subtrans_load(i, depth);
END LOOP;
END $$ LANGUAGE plpgsql;
构造一个预备事务,让后台 autovacuum 无法通过冻结数据推进系统中最老的事务 ID。
BEGIN;
SELECT pg_current_xact_id();
PREPARE TRANSACTION 't1';
注意:如果你需要使用预备事务,你会希望把 max_prepared_transactions 至少设置为 max_connections 一样大,这样每一个会话都可以有一个预备事务待处理。
使用 pgbench 并发 8 个会话调用上面的存储过程:
echo "CALL subtrans_test(128);" > test.sql
pgbench -n --time=7200 --client=8 --jobs=8 -f test.sql
上面的命令运行一段时间后(大约 20 分钟左右),数据库出现错误:“数据库不接受命令”,PostgreSQL 陷入停机状态。
ERROR: database is not accepting commands that assign new transaction IDs to avoid wraparound data loss in database "postgres"
HINT: Execute a database-wide VACUUM in that database.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.
注意:在出现上面的错误之前,数据库会频繁产生告警信息,比如
WARNING: database "postgres" must be vacuumed within 3000000 transactions。大量这类的日志信息很可能会导致系统出现磁盘空间不足的情况。
事务号分配场景: 内部原理
下面是我们在 PostgreSQL 中运行上面的存储过程时,数据库系统全局事务 ID 发生的变化:
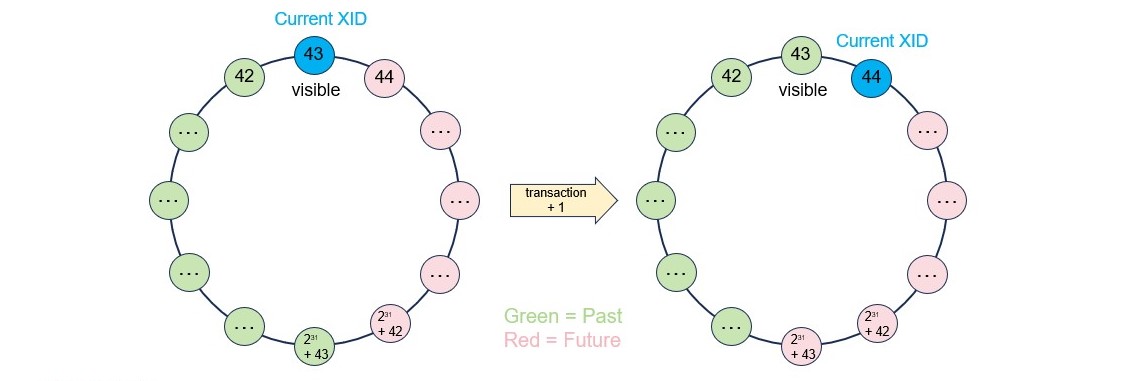
- PostgreSQL 使用了子事务,来实现存储函数中的异常处理代码块。
- 每个事务/子事务都有一个事务 ID,它有点像数据库系统的运行时间。
- 每行都有两个默认的隐藏属性 xmin 和 xmax,这两个属性分别保存了创建和更改它们的事务/子事务的 ID。
- 系统中最多出现的事务 ID 数目约为 20 亿,在超过该数目后,MVCC 的机制将无法正常工作。
事务号分配场景: 思考
问题影响
- 需要定期扫描所有数据行,进行事务 ID 的冻结操作,周期时长由 autovacuum_freeze_max_age 参数控制,默认为 2 亿次事务。
- 如果再叠加长事务/慢查询的发生,会出现事务 ID 耗尽,数据库停止服务。
- 系统需要存储管理所有未冻结事务的状态,容易出现 pg_xact、pg_subtrans 和 pg_multixact 缓存访问的等待事件,整体性能会下降。
冻结频率与事务吞吐量
在 PostgreSQL 中,元组冻结操作(通过VACUUM命令执行)的频率与每秒修改数据的事务数(TPS,包括 INSERT、UPDATE、DELETE 操作)成正比。由于 PostgreSQL 采用 32 位事务 ID(XID),其事务 ID 会在累计约 20 亿次事务后发生回卷,因此高吞吐系统(高写入 TPS)需要更频繁地执行冻结操作,以防止因事务 ID 回卷造成数据丢失。
数据表达到默认的 autovacuum_freeze_max_age 阈值的耗时,会随事务 ID 消耗速率的提升而缩短。
| 事务 ID 消耗速率(每秒) | 达到 20 亿事务阈值的时长 | 执行冻结操作的周期 |
|---|---|---|
| 1000 | 23 天 | 2.3 天 |
| 10000 | 2.3 天 | 5.5 小时 |
| 100000 | 5.5 小时 | 33 分钟 |
| 1000000 | 33 分钟 | 3.3 分钟 |
注意:以上数据基于持续、高吞吐量的写入业务场景测算,部分为理论值,旨在直观体现超高事务吞吐量对系统的影响。
应对方案
- 配置监控告警,检查事务 ID 耗尽
- 配置监控告警,检查子事务的使用情况
- 配置监控告警,检查长时间运行的事务
Redrock Postgres 的解决方案
Redrock Postgres 是基于回滚日志记录位置实现的子事务,这些子事务不过是事务执行过程中的一个临时标记。子事务使用和所属事务块同样的事务 ID,它们并不需要分配独立的事务 ID,不会对系统造成任何风险。
另外,在 Redrock Postgres 中,内部的事务 ID 是 8 字节的长度,可以近乎无限使用,无需担心事务 ID 用尽的风险。每个事务会记录回滚日志,用于回滚数据的修改和事务,事务状态的维护和管理更简单且更稳定。