March 14, 2024
Summary: in this tutorial, you will understand cost estimation for parallel execution plan.
Table of Contents
PostgreSQL parallel execution
In PostgreSQL 9.6 and higher, parallel execution of plans is a thing. Here’s how it works: the leader process creates (via postmaster) several worker processes. These processes then simultaneously execute a section of the plan in parallel. The results are then gathered at the Gather node by the leader process. While not occupied with gathering data, the leader process may participate in the parallel calculations as well.
You can disable this behavior by setting the parallel_leader_participation parameter to 0, but only in version 11 or higher.
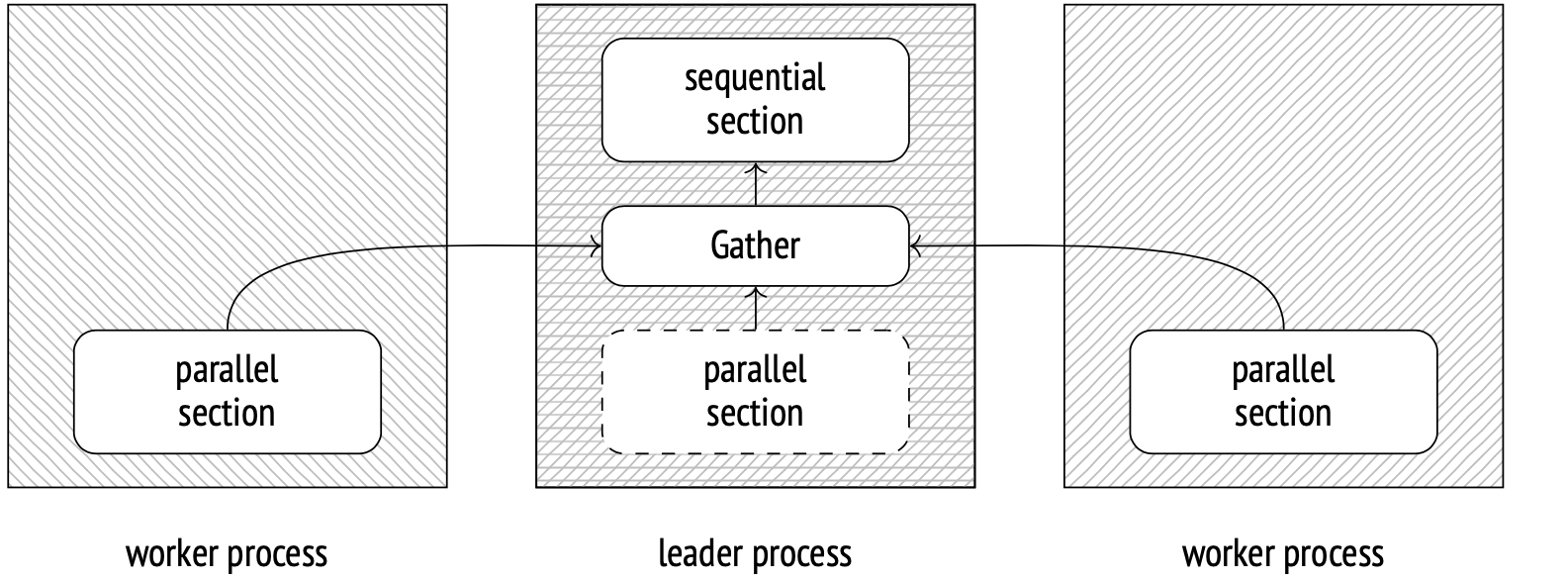
Spawning new processes and sending data between them add to the total cost, so you may often be better off not using parallel execution at all.
Besides, there are operations that simply can’t be executed in parallel. Even with the parallel mode enabled, the leader process will still execute some of the steps alone, sequentially.
Parallel sequential scan
The method’s name might sound controversial, claiming to be parallel and sequential at the same time, but that’s exactly what’s going on at the Parallel Seq Scan node. From the disk’s point of view, all file pages are fetched sequentially, same as they would be with a regular sequential scan. The fetching, however, is done by several processes working in parallel. The processes synchronize their fetching schedule in a special shared memory section in order to avoid fetching the same page twice.
The operating system, on the other hand, does not recognize this fetching as sequential. From its perspective, it’s just several processes requesting seemingly random pages. This breaks prefetching that serves us so well with regular sequential scan. The issue was fixed in PostgreSQL 14, when the system started assigning each parallel process several sequential pages to fetch at once instead of just one.
Parallel scanning by itself doesn’t help much with cost efficiency. In fact, all it does is it adds the cost of data transfers between processes on top of the regular page fetch cost. However, if the worker processes not only scan the rows, but also process them to some extent (for example, aggregate), then you may save a lot of time.
Example parallel plan with aggregation
Let’s start with a little test setup:
CREATE TABLE testpar (id integer, str text);
INSERT INTO testpar (id, str)
SELECT i, repeat(chr(65 + mod(i, 26)), 64) as str
FROM generate_series(1, 1000000) AS s(i);
ANALYZE testpar;
The optimizer sees this simple query with aggregation on a large table and proposes that the optimal strategy is the parallel mode:
EXPLAIN SELECT count(*) FROM testpar;
QUERY PLAN
-------------------------------------------------------------------------------------------
Finalize Aggregate (cost=16625.55..16625.56 rows=1 width=8)
-> Gather (cost=16625.33..16625.54 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=15625.33..15625.34 rows=1 width=8)
-> Parallel Seq Scan on testpar (cost=0.00..14583.67 rows=416667 width=0)
(5 rows)
All the nodes below Gather are the parallel section of the plan. It will be executed by all worker processes (2 of them are planned, in this case) and the leader process (unless disabled by the parallel_leader_participation option). The Gather node and all the nodes above it are executed sequentially by the leader process.
Consider the Parallel Seq Scan node, where the scanning itself happens. The rows field shows an estimate of rows to be processed by one process. There are 2 worker processes planned, and the leader process will assist too, so the rows estimate equals the total table row count divided by 2.4 (2 for the worker processes and 0.4 for the leader; the more there are workers, the less the leader contributes).
SELECT reltuples::numeric, round(reltuples / 2.4) AS per_process
FROM pg_class WHERE relname = 'testpar';
reltuples | per_process
-----------+-------------
1000000 | 416667
(1 row)
Parallel Seq Scan cost is calculated in mostly the same way as Seq Scan cost. We win time by having each process handle fewer rows, but we still read the table through-and-through, so the I/O cost isn’t affected:
SELECT round((
relpages * current_setting('seq_page_cost')::real +
reltuples / 2.4 * current_setting('cpu_tuple_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname = 'testpar';
round
----------
14583.67
(1 row)
The Partial Aggregate node aggregates all the data produced by the worker process (counts the rows, in this case).
The aggregate cost is calculated in the same way as before and added to the scan cost.
WITH t(startup_cost) AS (
SELECT 14583.67 + round((
reltuples / 2.4 * current_setting('cpu_operator_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname='testpar'
)
SELECT startup_cost,
startup_cost + round((
1 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost
FROM t;
startup_cost | total_cost
--------------+------------
15625.34 | 15625.35
(1 row)
The next node, Gather, is executed by the leader process. This node starts worker processes and gathers their output data.
The cost of starting up a worker process (or several; the cost doesn’t change) is defined by the parameter parallel_setup_cost (1000 by default). The cost of sending a single row from one process to another is set by parallel_tuple_cost (0.1 by default). The bulk of the node cost is the initialization of the parallel processes. It is added to the the Partial Aggregate node startup cost. There is also the transmission of two rows; this cost is added to the Partial Aggregate node’s total cost.
SELECT
15625.34 + round(
current_setting('parallel_setup_cost')::numeric,
2) AS setup_cost,
15625.35 + round(
current_setting('parallel_setup_cost')::numeric +
2 * current_setting('parallel_tuple_cost')::numeric,
2) AS total_cost;
setup_cost | total_cost
------------+------------
16625.34 | 16625.55
(1 row)
The Finalize Aggregate node joins together the partial data collected by the Gather node. Its cost is assessed just like with a regular Aggregate. The startup cost comprises the aggregation cost of three rows and the Gather node total cost (because Finalize Aggregate needs all its output to compute). The cherry on top of the total cost is the output cost of one resulting row.
WITH t(startup_cost) AS (
SELECT 16625.55 + round((
3 * current_setting('cpu_operator_cost')::real
)::numeric, 2)
FROM pg_class WHERE relname = 'testpar'
)
SELECT startup_cost,
startup_cost + round((
1 * current_setting('cpu_tuple_cost')::real
)::numeric, 2) AS total_cost
FROM t;
startup_cost | total_cost
--------------+------------
16625.56 | 16625.57
(1 row)