January 2, 2025
Summary: in this tutorial, you will learn how to optimize SELECT SQL queries by improving joins.
Table of Contents
Joins are frequently used in relational databases to select data coming from disparate tables. Understanding what join types are available and what they imply is crucial to achieve optimal performances. The following set of suggestions will help you identify the correct one.
Selecting inner joins
How
Both MySQL and PostgreSQL offer a variety of join types allowing you to precisely define the set of rows to retrieve from both sides of the join. All of them are useful for one or another reason but not all of them have the same performance. The INNER JOIN retrieving only the rows contained on both sides of the dataset usually has optimal performance. The LEFT, RIGHT, and OUTER joins on the other side, need to perform some additional work compared to the INNER JOIN therefore should be used only if really necessary.

Warning
Double check your queries, sometimes a query like the following seems legit:
SELECT *
FROM ORDERS LEFT JOIN USERS ON ORDERS.NAME = USERS.NAME
WHERE USERS.NAME IS NOT NULL
The above is using a LEFT JOIN to retrieve all the rows from ORDERS, but then is filtering for rows having USERS.NAME IS NOT NULL. Therefore is equivalent to an INNER JOIN.
Golden rule
Evaluate the exact requirements for the JOIN statement, and analyze the existing WHERE condition. If not strictly necessary, prefer an INNER JOIN.
Pro Tip
Check also if you can avoid a join altogether. If, for example, we are joining the data only to verify the presence of a row in another table, a subquery using EXISTS might be way faster than a join.
Using the same column type for joins
How
When joining two tables, ensure that the columns in the join condition are of the same type. Joining an integer Id column in one table with another customerId column defined as VARCHAR in another table will force the database to convert each Id to a string before comparing the results, slowing down the performance.

Warning
You can’t change the source field type at query time, but you can expose the data type inconsistency problem and fix it in the database table. When analyzing if the CustomerId field can be migrated from VARCHAR to INT, check that all the values in the column are integers indeed. If some of the values are not integers, you have a potential data quality problem.
Pro Tip
When in doubt, prefer more compact representations for your joining keys. If what you’re storing can be unambiguously defined as a number (e.g. a product code like 1234-678-234) prefer the number representation since it will:
- Use less disk
- Be faster to retrieve
- Be faster to join since integer comparison is quicker than the string version
However, beware of things that look like numbers but don’t quite behave like them - for instance, telephone numbers like 015555555 where the leading zero is significant.
Avoiding functions in joins
How
Similarly to the previous section, avoid unnecessary function usage in joins. Functions can prevent the database from using performance optimizations like leveraging indexes. Just think about the following query:
SELECT *
FROM users
JOIN orders ON UPPER(users.user_name) = orders.user_name
The above uses a function to transform the user_name field to upper case. However this could be a signal of poor data quality (and a missing foreign key) in the orders table that should be solved.
Warning
Queries like the one above can showcase a data quality problem solved at query time which is only a short term solution. Proper handling of data types and quality constraints should be a priority when designing data backend systems.
Golden rule
In a relational database, the joins between tables should be doable using the keys and foreign keys without any additional functions. If you find yourself needing to use a function, fix the data quality problem in the tables. In some edge cases using a function in conjunction with an index could help to speed up the comparison between complex or lengthy data types. For example, checking the equality between two long strings could potentially be accelerated by comparing initially only the first 50 characters, using the joining function UPPER(SUBSTR(users.user_name, 1, 50)) and an index on the same function.
Avoiding joins
How
Queries can be built over time by different people and have a lot of sequential steps in the shape of CTE (common table expression). Therefore it might be difficult to understand the actual needs in terms of data inputs and outputs. Most of the time, when writing a query, you can add an extra field “just in case it is necessary” at a later stage. However this could have tremendous effects on performance if the field is coming from a new table requiring a join.
Always evaluate the strict data needs of the query and include only the columns and the tables which contain this information.
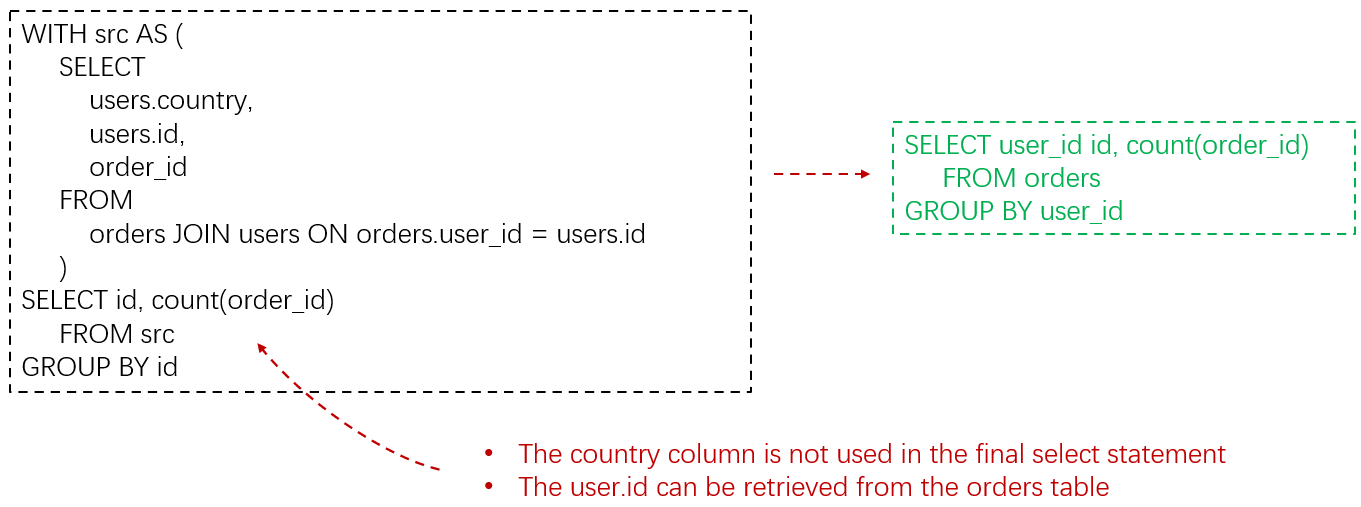
Warning
Double check if the join is needed to filter rows existing in both tables. In the example above, we could end up with incorrect results if there are user_id present in the orders table that are not stored in the id column of the users table.
Golden rule
Remove unnecessary joins. It is far more performant to generate a slimmer query to retrieve the overall dataset and then perform a lookup for more information only when necessary.
Pro Tip
The example explained above is just one case of JOIN overuse. Another example is when we are joining the data only to verify the presence of a row in another table. In such cases a subquery using EXISTS might be way faster than a join.