January 17, 2025
Summary: in this tutorial, you will learn how to tune multicolumn indexes in PostgreSQL.
Table of Contents
Multicolumn indexes
Even though the database creates the index for the primary key automatically, there is still room for manual refinements if the key consists of multiple columns. In that case the database creates an index on all primary key columns—a so-called multicolumn index (also known as composite or combined index). Note that the column order of a multicolumn index has great impact on its usability so it must be chosen carefully.
For the sake of demonstration, let’s assume there is a company merger. The employees of the other company are added to our EMPLOYEES table so it becomes ten times as large. There is only one problem: the EMPLOYEE_ID is not unique across both companies. We need to extend the primary key by an extra identifier—e.g., a subsidiary ID. Thus the new primary key has two columns: the EMPLOYEE_ID as before and the SUBSIDIARY_ID to reestablish uniqueness.
The index for the new primary key is therefore defined in the following way:
CREATE UNIQUE INDEX employees_pk
ON employees (employee_id, subsidiary_id);
A query for a particular employee has to take the full primary key into account—that is, the SUBSIDIARY_ID column also has to be used:
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123
AND subsidiary_id = 30;
Whenever a query uses the complete primary key, the database can use an Index Scan—no matter how many columns the index has.
Index not matched
But what happens when using only one of the key columns, for example, when searching all employees of a subsidiary?
SELECT first_name, last_name
FROM employees
WHERE subsidiary_id = 20;
The execution plan reveals that the database does not use the index. Instead it performs a Seq Scan. As a result the database reads the entire table and evaluates every row against the WHERE clause. The execution time grows with the table size: if the table grows tenfold, the Seq Scan takes ten times as long. The danger of this operation is that it is often fast enough in a small development environment, but it causes serious performance problems in production.
The database does not use the index because it cannot use single columns from a multicolumn index arbitrarily. A closer look at the index structure makes this clear.
A multicolumn index is just a B-tree index like any other that keeps the indexed data in a sorted list. The database considers each column according to its position in the index definition to sort the index entries. The first column is the primary sort criterion and the second column determines the order only if two entries have the same value in the first column and so on.
Important: A multicolumn index is one index across multiple columns.
The ordering of a two-column index is therefore like the ordering of a telephone directory: it is first sorted by surname, then by first name. That means that a two-column index does not support searching on the second column alone; that would be like searching a telephone directory by first name.
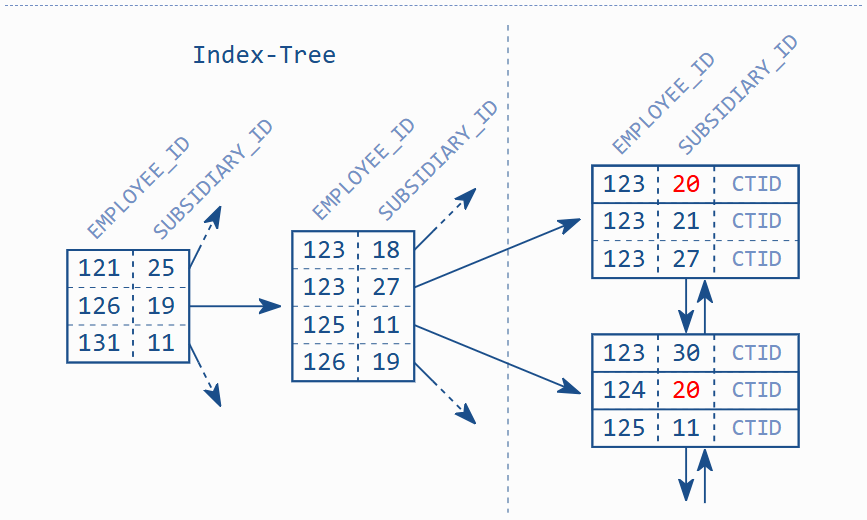
The index excerpt in above figure shows that the entries for subsidiary 20 are not stored next to each other. It is also apparent that there are no entries with SUBSIDIARY_ID = 20 in the tree, although they exist in the leaf nodes. The tree is therefore useless for this query.
Tip
Visualizing an index helps in understanding what queries the index supports. You can query the database to retrieve the entries in index order (using
LIMIT):SELECT <INDEX COLUMN LIST> FROM <TABLE> ORDER BY <INDEX COLUMN LIST> LIMIT 100;If you put the index definition and table name into the query, you will get a sample from the index. Ask yourself if the requested rows are clustered in a central place. If not, the index tree cannot help find that place.
How to tune?
We could, of course, add another index on SUBSIDIARY_ID to improve query speed. There is however a better solution—at least if we assume that searching on EMPLOYEE_ID alone does not make sense.
We can take advantage of the fact that the first index column is always usable for searching. Again, it is like a telephone directory: you don’t need to know the first name to search by last name. The trick is to reverse the index column order so that the SUBSIDIARY_ID is in the first position:
CREATE UNIQUE INDEX EMPLOYEES_PK
ON EMPLOYEES (SUBSIDIARY_ID, EMPLOYEE_ID);
Both columns together are still unique so queries with the full primary key can still use an Index Scan but the sequence of index entries is entirely different. The SUBSIDIARY_ID has become the primary sort criterion. That means that all entries for a subsidiary are in the index consecutively so the database can use the B-tree to find their location.
Important: The most important consideration when defining a multicolumn index is how to choose the column order so it can be used as often as possible.
The execution plan confirms that the database uses the “reversed” index. The SUBSIDIARY_ID alone is not unique anymore so the database must follow the leaf nodes in order to find all matching entries: it is therefore using the Bitmap Index Scan operation.
QUERY PLAN
----------------------------------------------------------------------------
Bitmap Heap Scan on employees (cost=24.63..1529.17 rows=1080 width=13)
Recheck Cond: (subsidiary_id = 2::numeric)
-> Bitmap Index Scan on employees_pk (cost=0.00..24.36 rows=1080 width=0)
Index Cond: (subsidiary_id = 2::numeric)
The PostgreSQL database uses two operations in this case: a Bitmap Index Scan followed by a Bitmap Heap Scan. It first fetches all results from the index (Bitmap Index Scan), then sorts the rows according to the physical storage location of the rows in the heap table and than fetches all rows from the table (Bitmap Heap Scan). This method reduces the number of random access IOs on the table.
In general, a database can use a multicolumn index when searching with the leading (leftmost) columns. An index with three columns can be used when searching for the first column, when searching with the first two columns together, and when searching using all columns.
Even though the two-index solution delivers very good SELECT performance as well, the single-index solution is preferable. It not only saves storage space, but also the maintenance overhead for the second index. The fewer indexes a table has, the better the INSERT, DELETE and UPDATE performance.
Conclusion
To define an optimal index you must understand more than just how indexes work—you must also know how the application queries the data. This means you have to know the column combinations that appear in the WHERE clause.
As a result, it can be very difficult to define an optimal index without an overview of the application’s access paths. Analyzing one single query individually and define an index, the index could not bring extra benefit for other queries. Database administrators may make similar mistakes as they might know the database schema but do not have deep insight into the access paths.
The only place where the technical database knowledge meets the functional knowledge of the business domain is the development department. Developers have a feeling for the data and know the access path. They can properly index to get the best benefit for the overall application without much effort.