February 18, 2024
Summary: in this tutorial, you will learn how to tune the estimated number of returned rows for a function.
Table of Contents
Introduction
When you reference/call functions in PostgreSQL the optimizer does not really know much about the cost nor the amount of rows that a function returns. This is not really surprising as it is hard to predict what the functions is doing and how many rows will be returned for a given set of input parameters. What you might not know is, that indeed you can tell the optimizer a bit more about your functions.
PostgreSQL offers ROWS and COST declarations for a function. These can be used for any PostgreSQL function written in any language. These declarations allow the function designer to dictate to the planner how many records to expect and provide a hint as to how expensive a function call is. COST is measured in CPU cycles. A higher COST number means more costly. For example a high cost function called in an AND where condition will not be called if any of the less costly functions result in a false evaluation. The number of ROWs as well as COST will give the planner a better idea of which strategy to use.
Use functions in FROM clause
Let’s start with a little test setup:
CREATE TABLE people
(
first_name character varying(50),
last_name character varying(50),
mi character(1),
name_key serial PRIMARY KEY
);
INSERT INTO people(first_name, last_name, mi)
SELECT a1.p1 || a2.p2 AS fname, a3.p3 || a1.p1 || a2.p2 AS lname, a3.p3 AS mi
FROM
(SELECT chr(65 + mod(CAST(random() * 1000 AS int) + 1, 26)) AS p1
FROM generate_series(1, 30)) AS a1
CROSS JOIN
(SELECT chr(65 + mod(CAST(random() * 1000 As int) + 1, 26)) AS p2
FROM generate_series(1, 20)) AS a2
CROSS JOIN
(SELECT chr(65 + mod(CAST(random() * 1000 AS int) + 1, 26)) AS p3
FROM generate_series(1, 100)) AS a3;
CREATE INDEX idx_people_last_name ON people (last_name);
ANALYZE people;
A simple table containing 60'000 rows and one index. In addition let’s create a simple function that will return a set of keys from that table:
CREATE FUNCTION fn_get_peoplebylname_key(lname varchar)
RETURNS SETOF int as $$
BEGIN
return query SELECT name_key FROM people WHERE last_name LIKE $1;
END $$ LANGUAGE plpgsql STABLE;
What is the optimizer doing when you call this function in FROM clause?
EXPLAIN (analyze) SELECT p.first_name, p.last_name, nkey
FROM fn_get_peoplebylname_key('MO%') as nkey
INNER JOIN people p ON p.name_key = nkey
WHERE p.first_name <> 'E';
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=1707.43..1730.05 rows=998 width=11) (actual time=20.986..21.034 rows=160 loops=1)
Hash Cond: (nkey.nkey = p.name_key)
-> Function Scan on fn_get_peoplebylname_key nkey (cost=0.25..10.25 rows=1000 width=4) (actual time=6.413..6.418 rows=160 loops=1)
-> Hash (cost=959.00..959.00 rows=59854 width=11) (actual time=14.350..14.350 rows=60000 loops=1)
Buckets: 65536 Batches: 1 Memory Usage: 2622kB
-> Seq Scan on people p (cost=0.00..959.00 rows=59854 width=11) (actual time=0.019..7.909 rows=60000 loops=1)
Filter: ((first_name)::text <> 'E'::text)
Planning time: 1.612 ms
Execution time: 24.283 ms
(9 rows)
The pgAdmin graphical explain plan shows nicely that a Hash Join strategy is taken.
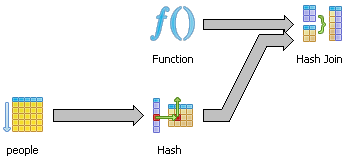
We know that only 160 rows actually returned but the optimizer is assuming that 1000 rows will be returned. This is the default and documented. So, no matter how many rows will really be returned, PostgreSQL will always estimate 1000.
Specify the estimated number of returned rows
PostgreSQL offers a ROWS parameter for the function definition. It is a positive number giving the estimated number of rows that the planner should expect the function to return. This is only allowed when the function is declared to return a set. The default assumption is 1000 rows.
To change the estimated number of returned rows for a function:
ALTER FUNCTION fn_get_peoplebylname_key(lname varchar) ROWS 100; -- a number less than before
The planner will detect that fn_get_peoplebylname_key() returns less rows and choose a better plan to execute the query. Looking again at the execution plan again:
EXPLAIN (analyze) SELECT p.first_name, p.last_name, nkey
FROM fn_get_peoplebylname_key('MO%') as nkey
INNER JOIN people p ON p.name_key = nkey
WHERE p.first_name <> 'E';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.54..668.25 rows=100 width=11) (actual time=5.725..5.978 rows=160 loops=1)
-> Function Scan on fn_get_peoplebylname_key nkey (cost=0.25..1.25 rows=100 width=4) (actual time=5.699..5.707 rows=160 loops=1)
-> Index Scan using name_key on people p (cost=0.29..6.67 rows=1 width=11) (actual time=0.001..0.001 rows=1 loops=160)
Index Cond: (name_key = nkey.nkey)
Filter: ((first_name)::text <> 'E'::text)
Planning time: 0.187 ms
Execution time: 6.010 ms
(7 rows)
The pgAdmin graphical explain plan shows nicely that a Nested Loop strategy is taken.
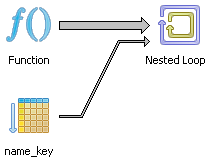
Instead of 1000 rows we now do see that only 100 rows was estimated which is what we specified to the function. By specifying the rows to a lower value, the planner changes strategies to a Nested Loop from a Hash Join.
Of course this is a very simple example and in reality you often might not be able to tell exactly how many rows will be returned from a function. But at least you can provide a better estimate as the default of 1000.