September 24, 2024
Summary: In this tutorial, you will learn the impact of full-page writes in PostgreSQL.
Table of Contents
Introduction
While tweaking postgresql.conf, you might have noticed there’s an option called full_page_writes. The comment next to it says something about partial page writes, and people generally leave it set to on – which is a good thing, as I’ll explain later in this article. It’s however useful to understand what full page writes do, because the impact on performance may be quite significant.
This is not a guide how to tune the server. There’s not much you can tweak, really, but I’ll show you how some application-level decisions (e.g. choice of data types) may interact with full page writes.
Partial Writes / Torn Pages
So what are full page writes about? As the comment in postgresql.conf says it’s a way to recover from partial page writes – PostgreSQL uses 8kB pages (by default), but other parts of the stack use different chunk sizes. Linux filesystems typically use 4kB pages (it’s possible to use smaller pages, but 4kB is the max on x86), and at the hardware level the old drives used 512B sectors while new devices often write data in larger chunks (often 4kB or even 8kB).
So when PostgreSQL writes the 8kB page, the other layers of the storage stack may break this into smaller chunks, managed separately. This presents a problem regarding write atomicity. The 8kB PostgreSQL page may be split into two 4kB filesystem pages, and then into 512B sectors. Now, what if the server crashes (power failure, kernel bug, …)?
Even if the server uses storage system designed to deal with such failures (SSDs with capacitors, RAID controllers with batteries, …), the kernel already split the data into 4kB pages. So it’s possible that the database wrote 8kB data page, but only part of that made it to disk before the crash.
At this point you’re now probably thinking that this is exactly why we have transaction log (WAL), and you’re right! So after starting the server, the database will read WAL (since the last completed checkpoint), and apply the changes again to make sure the data files are complete. Simple.
But there’s a catch – the recovery does not apply the changes blindly, it often needs to read the data pages etc. Which assumes that the page is not already borked in some way, for example due to a partial write. Which seems a bit self-contradictory, because to fix data corruption we assume there’s no data corruption.
Full page writes are a way around this conundrum – when modifying a page for the first time after a checkpoint, the whole page is written into WAL. This guarantees that during recovery, the first WAL record touching a page contains the whole page, eliminating the need to read the – possibly broken – page from data file.
Write amplification
Of course, the negative consequence of this is increased WAL size – changing a single byte on the 8kB page will log the whole into WAL. The full page write only happens on the first write after a checkpoint, so making checkpoints less frequent is one way to improve the situation – typically, there’s a short “burst” of full page writes after a checkpoint, and then relatively few full page writes until the end of a checkpoint.
UUID vs. BIGSERIAL keys
But there are some unexpected interactions with design decisions made at the application level. Let’s assume we have a simple table with primary key, either a BIGSERIAL or UUID, and we insert data into it. Will there be a difference in the amount of WAL generated (assuming we insert the same number of rows)?
It seems reasonable to expect both cases to produce about the same amount of WAL, but as the following charts illustrate, there’s a huge difference in practice.
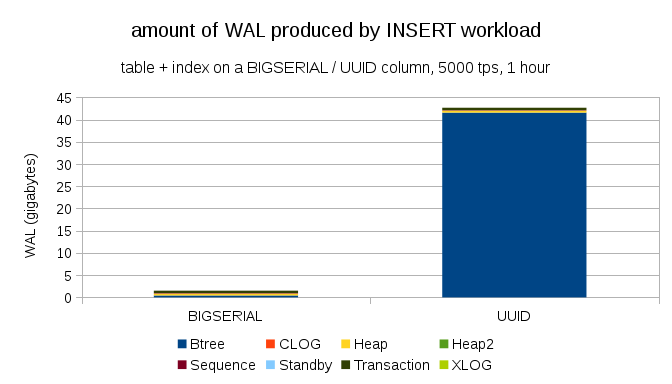
This shows the amount of WAL produced during a 1h benchmark, throttled to 5000 inserts per second. With BIGSERIAL primary key this produces ~2GB of WAL, while with UUID it’s more than 40GB. That’s quite a significant difference, and quite clearly most of the WAL is associated with index backing the primary key. Let’s look as types of WAL records.

Clearly, vast majority of the records are full-page images (FPI), i.e. the result of full-page writes. But why is this happening?
Of course, this is due to the inherent UUID randomness. With BIGSERIAL the values are sequential, and so get inserted to the same leaf pages in the btree index. As only the first modification to a page triggers the full-page write, only a tiny fraction of the WAL records are FPIs. With UUID it’s completely different case, of couse – the values are not sequential at all, in fact each insert is likely to touch completely new index leaf page (assuming the index is large enough).
There’s not much the database can do – the workload is simply random in nature, triggering many full-page writes.
It’s not difficult to get similar write amplification even with BIGSERIAL keys, of course. It only requires different workload – for example with UPDATE workload, randomly updating records with uniform distribution, the chart looks like this:

Suddenly, the differences between data types are gone – the access is random in both cases, resulting in almost exactly the same amount of WAL produced. Another difference is that most of the WAL is associated with “heap”, i.e. tables, and not indexes. The “HOT” cases were designed to allow HOT UPDATE optimization (i.e. update without having to touch an index), which pretty much eliminates all index-related WAL traffic.
But you might argue that most applications don’t update the whole data set. Usually, only a small subset of data is “active” – people only access posts from the last few days on a discussion forum, unresolved orders in an e-shop, etc. How does that change the results?
Thankfully, pgbench supports non-uniform distributions, and for example with exponential distribution touching 1% subset of data ~25% of the time, the chart looks like this:

And after making the distribution even more skewed, touching the 1% subset ~75% of the time:

This again shows how big difference the choice of data types may make, and also the importance of tuning for HOT updates.
8kB and 4kB pages
An interesting question is how much WAL traffic could we save by using smaller pages in PostgreSQL (which requires compiling a custom package). In the best case, it might save up to 50% WAL, thanks to logging only 4kB instead of 8kB pages. For the workload with uniformly distributed UPDATEs it looks like this:

So the save is not not exactly 50%, but reduction from ~140GB to ~90GB is still quite significant.
Do we still need full-page writes?
It might seems like a ridiculous after explaining the danger of partial writes, but maybe disabling full page writes might be a viable option, at least in some cases.
Firstly, I wonder whether modern Linux filesystems are still vulnerable to partial writes? The parameter was introduced in PostgreSQL 8.1 released in 2005, so perhaps some of the many filesystem improvements introduced since then make this a non-issue. Probably not universally for arbitrary workloads, but maybe assuming some additional condition (e.g. using 4kB page size in PostgreSQL) would be sufficient? Also, PostgreSQL never overwrites only a subset of the 8kB page – the whole page is always written out. Even if it’s still an issue, data checksums may be sufficient protection (it won’t fix the issue, but will at least let you know there’s a broken page).
Secondly, many systems nowadays rely on streaming replication replicas – instead of waiting for the server to reboot after a hardware issue (which can take quite a long time) and then spend more time performing recovery, the systems simply switch to a hot standby. If the database on the failed primary is removed (and then cloned from the new primary), partial writes are a non-issue.
But I guess if we started recommending that, then “I don’t know how the data got corrupted, I’ve just set full_page_writes=off on the systems!” would become one of the most common sentences right before death for DBAs (together with the “I’ve seen this snake on reddit, it’s not poisonous.”).
Summary
There’s not much you can do to tune full-page writes directly. For most workloads, most full-page writes happen right after a checkpoint, and then disappear until the next checkpoint. So it’s important to tune checkpoints not to happen too often.
Some application-level decisions may increase randomness of writes to tables and indexes – for example UUID values are inherently random, turning even simple INSERT workload into random index updates. The schema used in the examples was rather trivial – in practice there will be secondary indexes, foreign keys etc. But using BIGSERIAL primary keys internally (and keeping the UUID as surrogate keys) would at least reduce the write amplification.