March 4, 2024
Summary: in this tutorial, you will learn how to tune estimated number of distinct values.
Table of Contents
Introduction
The number of distinct values in a column is stored in the n_distinct field in pg_stats.
If n_distinct is negative, its absolute value instead represents the fraction of values that are distinct. For example, the value of −1 means that every item in the column is unique. When the number of distinct values reaches 10% of the number of rows or more, the analyzer switches to the fraction mode. It is assumed at this point that the proportion will generally remain the same when the data is modified.
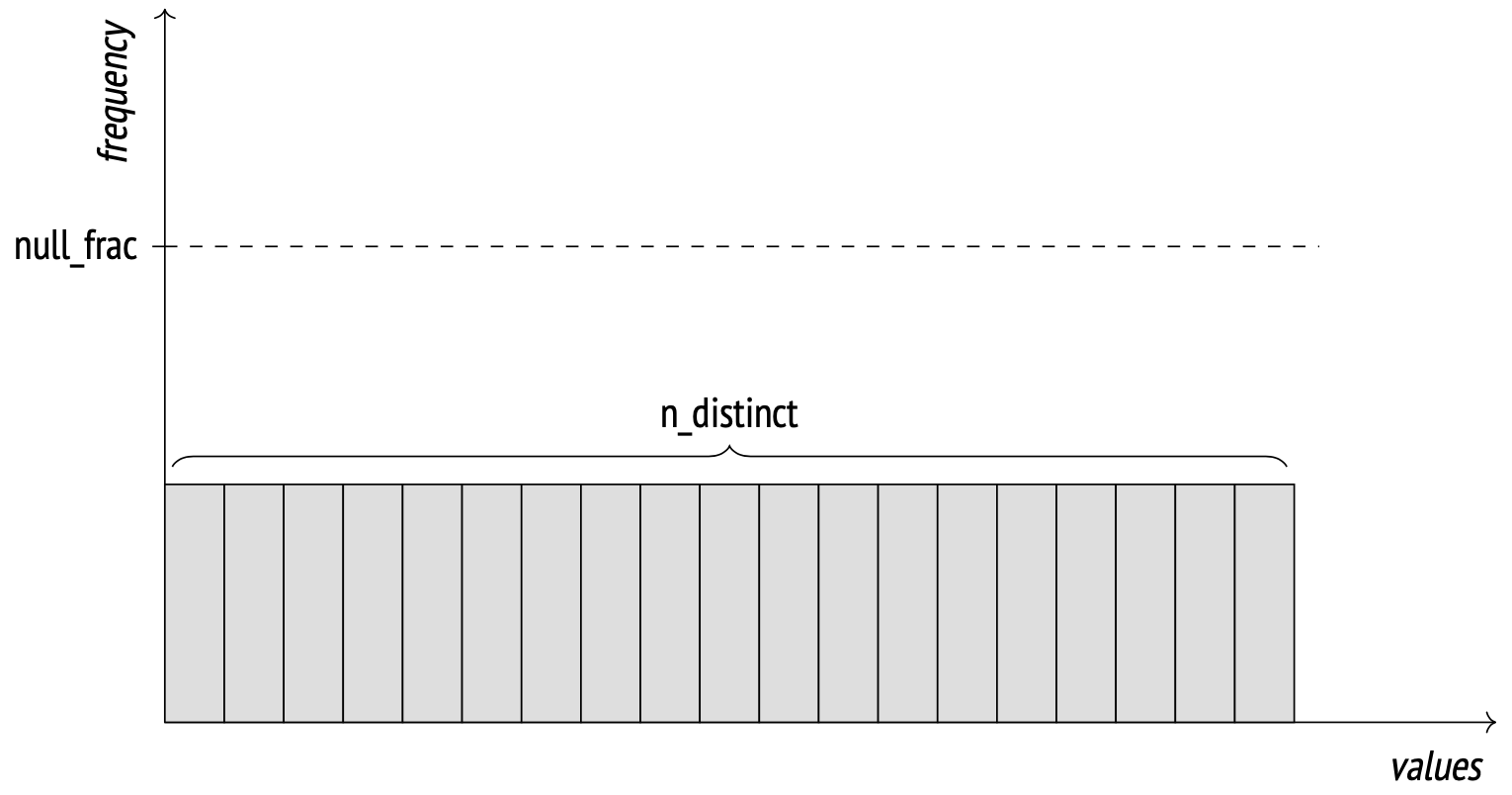
Example
Let’s start with a little test setup, generate some sample data from a continuous Gaussian random distribution:
CREATE TABLE test6 (id integer, val integer);
INSERT INTO test6 (id, val)
SELECT i,
CAST(cos(2 * pi() * random()) * sqrt(-2 * ln(random())) * 100 AS integer)
FROM generate_series(1, 100000) AS s(i);
ANALYZE test6;
The number of distinct values is useful in cases where data is distributed uniformly. Consider this cardinality estimation of a “column = expression” clause. If the value of expression is unknown at the planning stage, the planner assumes that expression is equally likely to return any value from the column.
EXPLAIN
SELECT * FROM test6 WHERE val = (
SELECT CAST(random() * 200 AS integer)
);
QUERY PLAN
----------------------------------------------------------
Seq Scan on test6 (cost=0.02..1498.02 rows=154 width=8)
Filter: (val = $0)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.02 rows=1 width=4)
(4 rows)
The InitPlan node is executed only once, and the value is then used instead of $0 in the main plan.
SELECT round(reltuples / s.n_distinct) AS rows
FROM pg_class
JOIN pg_stats s ON s.tablename = relname
WHERE s.tablename = 'test6'
AND s.attname = 'val';
rows
------
154
(1 row)
If all data is distributed uniformly, these statistics (together with min and max values) would be sufficient for an accurate estimation. Unfortunately, this estimation does not work as well for nonuniform distributions, which are much more common:
SELECT min(cnt), round(avg(cnt)) AS avg, max(cnt) FROM (
SELECT val, count(*) AS cnt
FROM test6 GROUP BY val
) t;
min | avg | max
-----+-----+-----
1 | 138 | 438
(1 row)
Tune statistics for number of distinct values
By tweaking the n_distinct settings when they are less than optimal, you can influence the query planner to produce better plans. Why this is necessary is mostly for large tables where the stat collector will not query the whole table to determine stats. The stats collector generally queries at most 10-30% of a table.
It’s always nice to have the stat collector do all these things for you especially if you have a table that is constantly updated and distinct counts can fluctuate a lot. For static tables you may just want to set them manually. So how do you know whether you should bother or not. Well you can check the current values stored in the n_distinct field in pg_stats, and the actual values:
-- estimated number of distinct values
SELECT n_distinct FROM pg_stats
WHERE tablename = 'test6' AND attname = 'val';
-- actual number of distinct values
SELECT count(DISTINCT val) FROM test6;
If the number of distinct values is calculated incorrectly (because the sample happened to be unrepresentative), you can set the value like this:
ALTER TABLE table_name ALTER COLUMN column_name SET (n_distinct = 100);