一月 17, 2025
摘要:在本教程中,您将学习如何在 PostgreSQL 中优化多列索引。
目录
多列索引
即使数据库自动为主键创建索引,但如果键由多个列组成,则仍会有手动优化的空间。在这种情况下,数据库会创建一个包含所有主键列的索引 — 所谓的多列索引(也称为复合索引或组合索引)。请注意,多列索引的列顺序对其实用性有很大影响,因此必须谨慎选择。
为了便于演示,我们假设需要合并一家公司。另一家公司的员工会被添加到我们的EMPLOYEES表中,因此该表会变得大十倍。只有一个问题:两家公司中的EMPLOYEE_ID并不是唯一的。我们需要通过一个额外的标识符(例如,子公司 ID),来扩展主键。因此,新的主键有两列:之前的EMPLOYEE_ID和SUBSIDIARY_ID,以重建唯一性。
因此,新的主键索引会按以下方式定义:
CREATE UNIQUE INDEX employees_pk
ON employees (employee_id, subsidiary_id);
针对一个特定员工的查询必须匹配完整的主键列,也就是说,还必须包含SUBSIDIARY_ID列:
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123
AND subsidiary_id = 30;
每当一个查询使用了完整的主键列时,数据库都可以使用Index Scan — 无论索引包含了多少列。
索引不匹配
但是,如果只使用了主键中的一个列,例如,在搜索子公司的所有员工时,会发生什么情况?
SELECT first_name, last_name
FROM employees
WHERE subsidiary_id = 20;
执行计划显示了数据库没有使用索引。相反,它执行了一次Seq Scan。因此,数据库会读取整个表,并根据WHERE子句计算每一行。执行时间随着表大小的增加而增加:如果表增长了 10 倍,则Seq Scan花费的时间也是 10 倍。该操作的危险在于,在小型开发环境中,它通常足够快,但在生产环境中会产生严重的性能问题。
数据库没有使用索引,是因为它不能任意使用多列索引中的单个列。仔细查看索引结构,可以清楚地看出这一点。
多列索引只是一个 B 树索引,就像任何其他索引一样,它将索引数据保存在排序的列表中。数据库根据索引定义中列的位置,比较每一列,对索引条目进行排序。第一列是主要排序判据,在两个条目的第一列具有相同的值时,才用第二列来确定顺序,依此类推。
重要:复合索引是跨多个列的一个索引。
因此,一个两列索引的排序类似于电话簿的排序:它首先按姓氏排序,然后按名字排序。这意味着两列索引不支持单独搜索第二列;这就像按名字搜索电话簿一样。
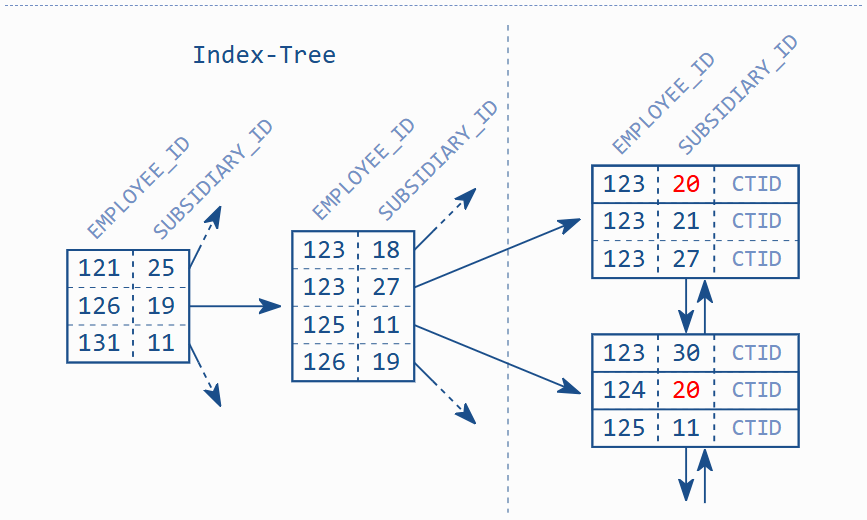
上图中的索引部分显示了,子公司编号为 20 的条目并未彼此相邻存储。同样明显的是,B 树中没有SUBSIDIARY_ID = 20的条目,尽管它们存在于叶节点中。因此,该索引对于此查询毫无用处。
提示
可视化一个索引有助于了解索引支持哪些查询。您可以查询数据库,以按索引顺序检索条目(使用
LIMIT):SELECT <INDEX COLUMN LIST> FROM <TABLE> ORDER BY <INDEX COLUMN LIST> LIMIT 100;你可以将索引定义和表名放入查询中,这样可以从索引中获取一个样本结果。问问自己,请求的行是否聚集在一个中心位置。否则,索引树无法帮助查询找到该位置。
如何调优?
当然,我们可以添加另一个SUBSIDIARY_ID上的索引,来提高查询速度。然而,有一个更好的解决方案 — 至少,如果能假设我们不会去单独搜索EMPLOYEE_ID的话。
我们可以利用一个事实:第一个索引列始终可以用于搜索。同样,它就像一个电话簿:您无需知道名字,即可按姓氏搜索。诀窍是反转索引列的顺序,以让SUBSIDIARY_ID位于第一个位置:
CREATE UNIQUE INDEX EMPLOYEES_PK
ON EMPLOYEES (SUBSIDIARY_ID, EMPLOYEE_ID);
这样两个列一起仍然是唯一的,因此包含完整主键列的查询仍然可以使用Index Scan,但索引条目的顺序完全不同。SUBSIDIARY_ID已成为主要的排序判据。这意味着一个子公司的所有条目会连续地位于索引中,因此数据库可以使用 B 树来查找它们的位置。
重要:定义多列索引时,最重要的考虑点是如何选择列的顺序,以便可以尽可能频繁地使用到索引。
执行计划确认数据库使用了 “反转后” 索引。单独的SUBSIDIARY_ID不再是唯一的了,因此数据库必须跟从叶节点,才能找到所有匹配的条目:因此它使用了Bitmap Index Scan操作。
QUERY PLAN
----------------------------------------------------------------------------
Bitmap Heap Scan on employees (cost=24.63..1529.17 rows=1080 width=13)
Recheck Cond: (subsidiary_id = 2::numeric)
-> Bitmap Index Scan on employees_pk (cost=0.00..24.36 rows=1080 width=0)
Index Cond: (subsidiary_id = 2::numeric)
在这种情况下,PostgreSQL 数据库使用了两种操作:一个Bitmap Index Scan,后跟一个Bitmap Heap Scan。它首先以Bitmap Index Scan从索引中获取所有结果,然后根据堆表行的物理存储位置对行进行排序,然后以Bitmap Heap Scan从表中获取所有行。此方法可减少表上的随机访问 IO 数。
通常,数据库在使用前置列(最左侧的列)进行搜索时,可以使用到多列索引。对于包含三个列的索引,在搜索第一列,或者同时使用前两列进行搜索,以及使用所有列进行搜索时,都可以使用到多列索引。
尽管两个索引的解决方案也能提供非常好的SELECT性能,但单个索引的解决方案更可取。它不仅可以节省存储空间,还可以节省第二个索引的维护开销。表的索引越少,INSERT、DELETE和UPDATE的性能就越好。
结论
要定义一个最佳的索引,您不仅必须了解索引的工作原理,还必须了解应用程序如何查询数据。这意味着您必须知道WHERE子句中出现的列的组合。
因此,在缺乏对应用程序访问路径的概览认识的情况下,要定义最佳的索引会非常困难。单独地分析某一个查询,定义出来的索引,往往很少能为其他查询带来额外的好处。数据库管理员可能会犯类似的错误,因为他们可能了解数据库架构,但对访问路径没有深入的了解。
数据库技术上的知识,与业务领域的知识相结合的唯一地方是开发部门。开发人员拥有对数据的认知,并且知道访问路径。他们可以正确地创建索引,以轻松获得整个应用程序的最大好处。